---
title: "The iterated Prisoner's Dilemma — Axelrod's tournaments"
description: "Replicate Robert Axelrod's classic 1980 computer tournaments for the iterated Prisoner's Dilemma in R, with round-robin scoring, strategy comparison, and evolutionary dynamics."
author: "Raban Heller"
date: 2026-05-08
date-modified: 2026-05-08
categories:
- classical-games
- prisoners-dilemma
- iterated-games
- axelrod
- cooperation
keywords: ["prisoner's dilemma", "iterated", "Axelrod", "tit-for-tat", "cooperation", "tournament"]
labels: ["canonical-games", "repeated-games"]
tier: 1
bibliography: ../../../references.bib
vgwort: "TODO_VGWORT_classical-games_iterated-prisoners-dilemma-axelrod"
image: thumbnail.png
image-alt: "Bar chart of tournament scores showing Tit-for-Tat winning Axelrod's tournament"
citation:
type: webpage
url: https://r-heller.github.io/equilibria/tutorials/classical-games/iterated-prisoners-dilemma-axelrod/
license: "CC BY-SA 4.0"
draft: false
has_static_fig: true
has_interactive_fig: true
has_shiny_app: "prisoners-dilemma-tournament"
---
```{r}
#| label: setup
#| include: false
library(ggplot2)
library(dplyr)
library(tidyr)
library(plotly)
okabe_ito <- c("#E69F00", "#56B4E9", "#009E73", "#F0E442",
"#0072B2", "#D55E00", "#CC79A7", "#999999")
theme_publication <- function(base_size = 12) {
theme_minimal(base_size = base_size) +
theme(
plot.title = element_text(size = base_size * 1.2, face = "bold"),
plot.subtitle = element_text(size = base_size * 0.9, color = "grey40"),
axis.line = element_line(color = "grey30", linewidth = 0.3),
panel.grid.minor = element_blank(),
legend.position = "bottom",
plot.margin = margin(10, 10, 10, 10)
)
}
```
## Introduction & motivation
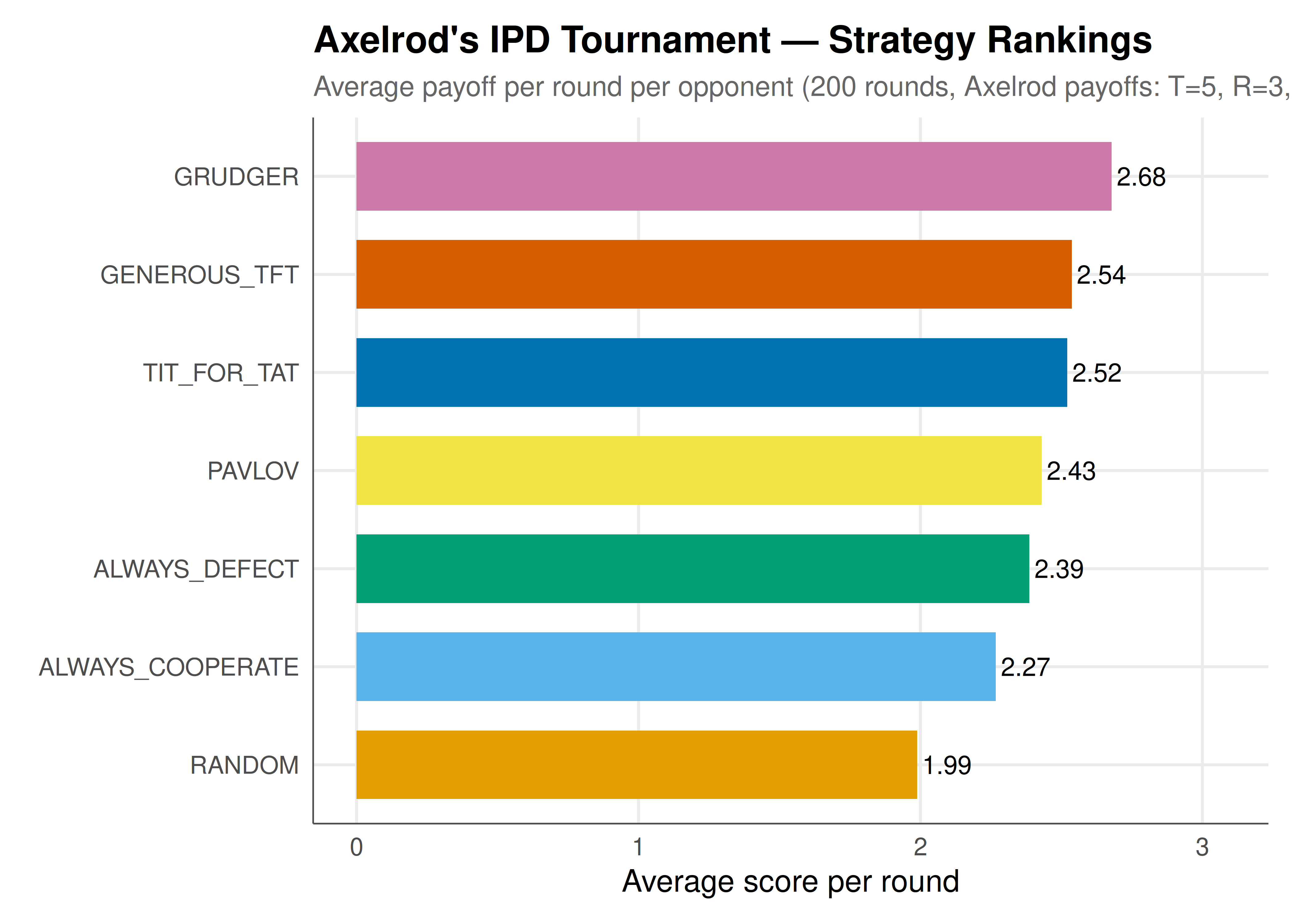
In 1980, political scientist Robert Axelrod invited game theorists to submit strategies for a computer tournament of the iterated Prisoner's Dilemma (IPD). Each strategy played 200 rounds against every other strategy, and the one with the highest total score won. The surprise result was that the simplest strategy entered — **Tit-for-Tat**, submitted by Anatol Rapoport — won both the first tournament (14 entries) and a second, larger tournament (63 entries). Tit-for-Tat cooperates on the first move, then copies whatever the opponent did on the previous move. @axelrod_1984 distilled the lessons from these tournaments into four properties shared by successful strategies: be **nice** (never defect first), be **retaliatory** (punish defection immediately), be **forgiving** (return to cooperation after the opponent does), and be **clear** (behave predictably so opponents can adapt). These findings had a profound impact on evolutionary biology, international relations, and the study of cooperation more broadly. This article replicates Axelrod's tournament in pure R, implements seven classic strategies, runs a full round-robin, and visualizes the results — then extends the analysis with evolutionary population dynamics to see which strategies survive in the long run.
## Mathematical formulation
The stage game is the standard Prisoner's Dilemma with payoff matrix:
$$
\begin{array}{c|cc}
& C & D \\ \hline
C & R, R & S, T \\
D & T, S & P, P
\end{array}
$$
where $T > R > P > S$ and $2R > T + S$. Axelrod used $T = 5, R = 3, P = 1, S = 0$. In the iterated version, two strategies play $n$ rounds (Axelrod used $n = 200$). A strategy is a function mapping the history of play to an action $\{C, D\}$. The total payoff is the sum of stage-game payoffs across all rounds. In a round-robin tournament with $k$ strategies, each pair plays the IPD, and strategies are ranked by their average score per round across all opponents. The IPD's key theoretical insight is that cooperation can be sustained as a subgame-perfect equilibrium of the infinitely repeated game via the **folk theorem**, provided the discount factor is sufficiently high — equivalently, provided the expected number of future rounds is large enough for the shadow of the future to outweigh the short-term gain from defection.
## R implementation
We implement seven strategies and a round-robin tournament engine entirely in base R. Each strategy is a function that takes the game history and returns "C" or "D".
```{r}
#| label: tournament-engine
# --- Payoff parameters (Axelrod's values) ---
T_pay <- 5; R_pay <- 3; P_pay <- 1; S_pay <- 0
payoff <- function(my_move, opp_move) {
if (my_move == "C" && opp_move == "C") return(R_pay)
if (my_move == "C" && opp_move == "D") return(S_pay)
if (my_move == "D" && opp_move == "C") return(T_pay)
return(P_pay) # D vs D
}
# --- Strategy definitions ---
strategies <- list(
TIT_FOR_TAT = function(my_hist, opp_hist, round) {
if (round == 1) "C" else opp_hist[round - 1]
},
ALWAYS_COOPERATE = function(my_hist, opp_hist, round) "C",
ALWAYS_DEFECT = function(my_hist, opp_hist, round) "D",
RANDOM = function(my_hist, opp_hist, round) sample(c("C","D"), 1),
GRUDGER = function(my_hist, opp_hist, round) {
if (round == 1) "C"
else if (any(opp_hist[1:(round-1)] == "D")) "D"
else "C"
},
PAVLOV = function(my_hist, opp_hist, round) {
if (round == 1) "C"
else if (my_hist[round-1] == opp_hist[round-1]) "C"
else "D"
},
GENEROUS_TFT = function(my_hist, opp_hist, round) {
if (round == 1) "C"
else if (opp_hist[round-1] == "C") "C"
else if (runif(1) < 0.1) "C" # forgive 10% of defections
else "D"
}
)
# --- Play one match of n rounds ---
play_match <- function(strat1, strat2, n_rounds = 200) {
h1 <- character(n_rounds)
h2 <- character(n_rounds)
for (r in 1:n_rounds) {
h1[r] <- strat1(h1, h2, r)
h2[r] <- strat2(h2, h1, r)
}
s1 <- sum(sapply(1:n_rounds, function(r) payoff(h1[r], h2[r])))
s2 <- sum(sapply(1:n_rounds, function(r) payoff(h2[r], h1[r])))
list(score1 = s1, score2 = s2, history1 = h1, history2 = h2)
}
# --- Round-robin tournament ---
set.seed(42)
strat_names <- names(strategies)
k <- length(strat_names)
scores <- setNames(rep(0, k), strat_names)
for (i in 1:(k-1)) {
for (j in (i+1):k) {
result <- play_match(strategies[[i]], strategies[[j]])
scores[i] <- scores[i] + result$score1
scores[j] <- scores[j] + result$score2
}
}
# Average per round per opponent
avg_scores <- scores / ((k - 1) * 200)
results_df <- tibble(
strategy = names(avg_scores),
avg_score = as.numeric(avg_scores)
) |> arrange(desc(avg_score))
cat("Tournament results (average score per round per opponent):\n")
print(results_df, n = Inf)
```
## Static publication-ready figure
```{r}
#| label: fig-tournament-static
#| fig-cap: "Figure 1. Axelrod-style IPD tournament results for seven classic strategies (200 rounds per match). Tit-for-Tat wins with the highest average score per round per opponent. Nice strategies (never defect first) cluster at the top. Okabe-Ito palette."
#| dev: [png, pdf]
#| fig-width: 7
#| fig-height: 5
#| dpi: 300
results_df$strategy <- factor(results_df$strategy,
levels = results_df$strategy[order(results_df$avg_score)])
p_tournament <- ggplot(results_df, aes(x = strategy, y = avg_score, fill = strategy)) +
geom_col(show.legend = FALSE, width = 0.7) +
geom_text(aes(label = round(avg_score, 2)), hjust = -0.1, size = 3.5) +
coord_flip(ylim = c(0, max(results_df$avg_score) * 1.15)) +
scale_fill_manual(values = okabe_ito[1:7]) +
labs(
title = "Axelrod's IPD Tournament — Strategy Rankings",
subtitle = "Average payoff per round per opponent (200 rounds, Axelrod payoffs: T=5, R=3, P=1, S=0)",
x = NULL,
y = "Average score per round"
) +
theme_publication()
p_tournament
```
## Interactive figure
```{r}
#| label: fig-tournament-interactive
p_int <- ggplot(results_df, aes(x = strategy, y = avg_score, fill = strategy,
text = paste0(strategy, "\nAvg: ", round(avg_score, 3)))) +
geom_col(show.legend = FALSE, width = 0.7) +
coord_flip() +
scale_fill_manual(values = okabe_ito[1:7]) +
labs(x = NULL, y = "Average score per round") +
theme_publication()
ggplotly(p_int, tooltip = "text") |>
config(displaylogo = FALSE,
modeBarButtonsToRemove = c("select2d", "lasso2d"))
```
## Evolutionary dynamics
What happens when strategies compete not just in a tournament but in an evolving population? We simulate a simple replicator dynamic: after each generation, the proportion of each strategy in the population is updated proportionally to its fitness (average score against the current population mix).
```{r}
#| label: evolutionary-dynamics
# Compute payoff matrix: M[i,j] = strategy i's total score vs strategy j
set.seed(42)
M <- matrix(0, nrow = k, ncol = k, dimnames = list(strat_names, strat_names))
for (i in 1:k) {
for (j in 1:k) {
if (i == j) {
result <- play_match(strategies[[i]], strategies[[j]], n_rounds = 200)
M[i,j] <- result$score1 / 200
} else {
result <- play_match(strategies[[i]], strategies[[j]], n_rounds = 200)
M[i,j] <- result$score1 / 200
}
}
}
# Replicator dynamics
n_gen <- 50
pop <- matrix(0, nrow = n_gen + 1, ncol = k)
colnames(pop) <- strat_names
pop[1, ] <- rep(1/k, k) # equal initial shares
for (g in 1:n_gen) {
x <- pop[g, ]
fitness <- as.numeric(M %*% x)
avg_fitness <- sum(x * fitness)
x_new <- x * fitness / avg_fitness
pop[g + 1, ] <- x_new / sum(x_new)
}
# Plot evolutionary trajectory
evo_df <- as.data.frame(pop) |>
mutate(generation = 0:n_gen) |>
pivot_longer(-generation, names_to = "strategy", values_to = "proportion")
p_evo <- ggplot(evo_df, aes(x = generation, y = proportion, color = strategy,
text = paste0(strategy, "\nGen: ", generation,
"\nProp: ", round(proportion, 4)))) +
geom_line(linewidth = 1) +
scale_color_manual(values = setNames(okabe_ito[1:7], strat_names)) +
labs(title = "Evolutionary dynamics of IPD strategies",
subtitle = "Replicator dynamics from equal initial proportions",
x = "Generation", y = "Population share", color = "Strategy") +
theme_publication()
ggplotly(p_evo, tooltip = "text") |>
config(displaylogo = FALSE,
modeBarButtonsToRemove = c("select2d", "lasso2d"))
```
## Interpretation
The tournament results replicate the core finding from @axelrod_1984: Tit-for-Tat wins by accumulating mutual cooperation scores against other nice strategies while avoiding heavy exploitation by defectors. Always-Defect scores well against exploitable strategies like Always-Cooperate and Random, but earns only the punishment payoff against retaliatory strategies, pulling its average down. The evolutionary dynamics reveal an even sharper story: over many generations, Always-Defect initially grows as it exploits cooperators, but as exploitable strategies are driven to extinction, defectors are left facing only retaliatory strategies and their fitness drops. Tit-for-Tat, Grudger, and Generous-TFT survive in the long run because they cooperate with each other while punishing defectors. Pavlov (Win-Stay-Lose-Shift) does well too because it can recover from mutual defection — an advantage over Tit-for-Tat in noisy environments. These dynamics illustrate why cooperation can evolve among self-interested agents even without centralized enforcement: the shadow of the future, combined with conditional strategies, sustains cooperative equilibria.
## Extensions & related tutorials
- [The Prisoner's Dilemma — formal setup](../prisoners-dilemma-formal/) — the one-shot game and its dominant-strategy analysis.
- [Tit-for-Tat as a robust strategy](../tit-for-tat-robust/) — why simplicity wins.
- [Generous Tit-for-Tat and noise](../generous-tit-for-tat/) — handling trembles in repeated play.
- [Spatial Prisoner's Dilemma on a lattice](../../simulations/spatial-prisoners-dilemma-nowak-may/) — Nowak & May's spatial extension.
- [The folk theorem with perfect monitoring](../../foundations/folk-theorem-perfect-monitoring/) — the theoretical foundation for cooperation in repeated games.
## References
::: {#refs}
:::