---
title: "Entropy and the value of information in strategic games"
description: "Apply Shannon entropy to game-theoretic information sets, quantify uncertainty reduction, and compare the value of perfect versus imperfect information using R implementations."
author: "Raban Heller"
date: 2026-05-08
categories:
- information-theory
- entropy
- value-of-information
keywords: ["Shannon entropy", "value of information", "information sets", "perfect information", "imperfect information", "game theory", "R"]
labels: ["information-theory", "strategic-uncertainty"]
tier: 1
bibliography: ../../../references.bib
vgwort: "TODO_VGWORT_information-theory_entropy-and-strategic-information"
image: thumbnail.png
image-alt: "Bar chart comparing Shannon entropy across different game-theoretic information structures"
citation:
type: webpage
url: https://r-heller.github.io/equilibria/tutorials/information-theory/entropy-and-strategic-information/
license: "CC BY-SA 4.0"
draft: false
has_static_fig: true
has_interactive_fig: true
---
```{r}
#| label: setup
#| include: false
library(ggplot2)
library(dplyr)
library(tidyr)
library(plotly)
okabe_ito <- c("#E69F00", "#56B4E9", "#009E73", "#F0E442",
"#0072B2", "#D55E00", "#CC79A7", "#999999")
theme_publication <- function(base_size = 12) {
theme_minimal(base_size = base_size) +
theme(
plot.title = element_text(size = base_size * 1.2, face = "bold"),
plot.subtitle = element_text(size = base_size * 0.9, color = "grey40"),
axis.line = element_line(color = "grey30", linewidth = 0.3),
panel.grid.minor = element_blank(),
legend.position = "bottom",
plot.margin = margin(10, 10, 10, 10)
)
}
```
## Introduction & motivation
In strategic interactions, what you know — and what you know your opponent knows — can be worth more than any payoff in the matrix. Shannon entropy, the foundational measure of uncertainty from information theory, provides a precise language for quantifying this strategic ignorance. When a player faces an information set containing multiple nodes, their uncertainty about the true game state can be measured in bits. The reduction of that uncertainty — through signals, observations, or communication — constitutes the value of information. Game theorists distinguish between perfect information (every information set is a singleton, as in chess) and imperfect information (some sets contain multiple nodes, as in poker). The difference is not merely categorical: entropy lets us place it on a continuous scale. A player holding a hand in poker has partial information — some entropy has been resolved, but residual uncertainty remains about opponents' holdings. The value of perfect information (VPI) is the expected payoff gain from resolving all uncertainty before acting, while the value of imperfect information depends on the specific signal structure. This tutorial formalises these concepts using Shannon's entropy, implements them in R, and visualises how information value varies across different game structures. Understanding these foundations is essential for mechanism design (where the principal chooses what information to reveal), Bayesian games (where players update beliefs), and modern applications in algorithmic game theory where information asymmetries are deliberately engineered.
## Mathematical formulation
Let $\Theta = \{\theta_1, \dots, \theta_n\}$ be a finite set of game states (nature's moves) with prior probability distribution $p(\theta_i)$. The **Shannon entropy** of the state uncertainty is:
$$
H(\Theta) = -\sum_{i=1}^{n} p(\theta_i) \log_2 p(\theta_i)
$$
with the convention $0 \log_2 0 = 0$. Entropy is maximised at $\log_2 n$ when the distribution is uniform and equals zero when the state is known with certainty.
Given a signal $S$ that induces posterior beliefs $p(\theta | s)$, the **conditional entropy** is:
$$
H(\Theta | S) = \sum_{s} p(s) \left[ -\sum_{i} p(\theta_i | s) \log_2 p(\theta_i | s) \right]
$$
The **mutual information** $I(\Theta; S) = H(\Theta) - H(\Theta | S) \geq 0$ measures how many bits the signal resolves.
In a game-theoretic context, the **value of perfect information** (VPI) is the expected payoff difference between the informed and uninformed decision:
$$
\text{VPI} = \sum_{i} p(\theta_i) \max_a u(a, \theta_i) - \max_a \sum_{i} p(\theta_i) u(a, \theta_i)
$$
where $u(a, \theta)$ is the payoff from action $a$ in state $\theta$. VPI is always non-negative — information never hurts a single decision-maker (though in games, this need not hold).
## R implementation
We implement functions to compute Shannon entropy, conditional entropy, mutual information, and the value of perfect versus imperfect information for a simple decision problem embedded in a game-theoretic context.
```{r}
#| label: entropy-implementation
# Shannon entropy in bits
shannon_entropy <- function(p) {
p <- p[p > 0] # remove zeros
-sum(p * log2(p))
}
# Conditional entropy H(Theta | S)
conditional_entropy <- function(joint) {
# joint is a matrix: rows = states, cols = signals
# joint[i,j] = P(theta_i, s_j)
p_s <- colSums(joint)
h_cond <- 0
for (j in seq_along(p_s)) {
if (p_s[j] > 0) {
posterior <- joint[, j] / p_s[j]
h_cond <- h_cond + p_s[j] * shannon_entropy(posterior)
}
}
h_cond
}
# Value of perfect information
value_of_info <- function(prior, payoff_matrix) {
# prior: vector of state probabilities
# payoff_matrix: actions x states
informed <- sum(prior * apply(payoff_matrix, 2, max))
uninformed <- max(payoff_matrix %*% prior)
list(vpi = informed - uninformed,
informed_payoff = informed,
uninformed_payoff = uninformed)
}
# --- Example: 2-state, 2-action decision problem ---
prior <- c(0.5, 0.5)
payoff_mat <- matrix(c(10, 2, 3, 8), nrow = 2, byrow = TRUE,
dimnames = list(c("Attack", "Defend"),
c("State_A", "State_B")))
cat("Prior entropy:", shannon_entropy(prior), "bits\n")
cat("Payoff matrix:\n"); print(payoff_mat)
voi <- value_of_info(prior, payoff_mat)
cat(sprintf("Uninformed expected payoff: %.1f\n", voi$uninformed_payoff))
cat(sprintf("Informed expected payoff: %.1f\n", voi$informed_payoff))
cat(sprintf("Value of perfect info: %.1f\n", voi$vpi))
# --- Varying prior and computing entropy + VPI ---
results <- tibble(
p_A = seq(0.01, 0.99, by = 0.01),
p_B = 1 - p_A,
entropy = mapply(function(a, b) shannon_entropy(c(a, b)), p_A, p_B),
vpi = mapply(function(a, b) {
value_of_info(c(a, b), payoff_mat)$vpi
}, p_A, p_B)
)
```
## Static publication-ready figure
```{r}
#| label: fig-entropy-vpi-static
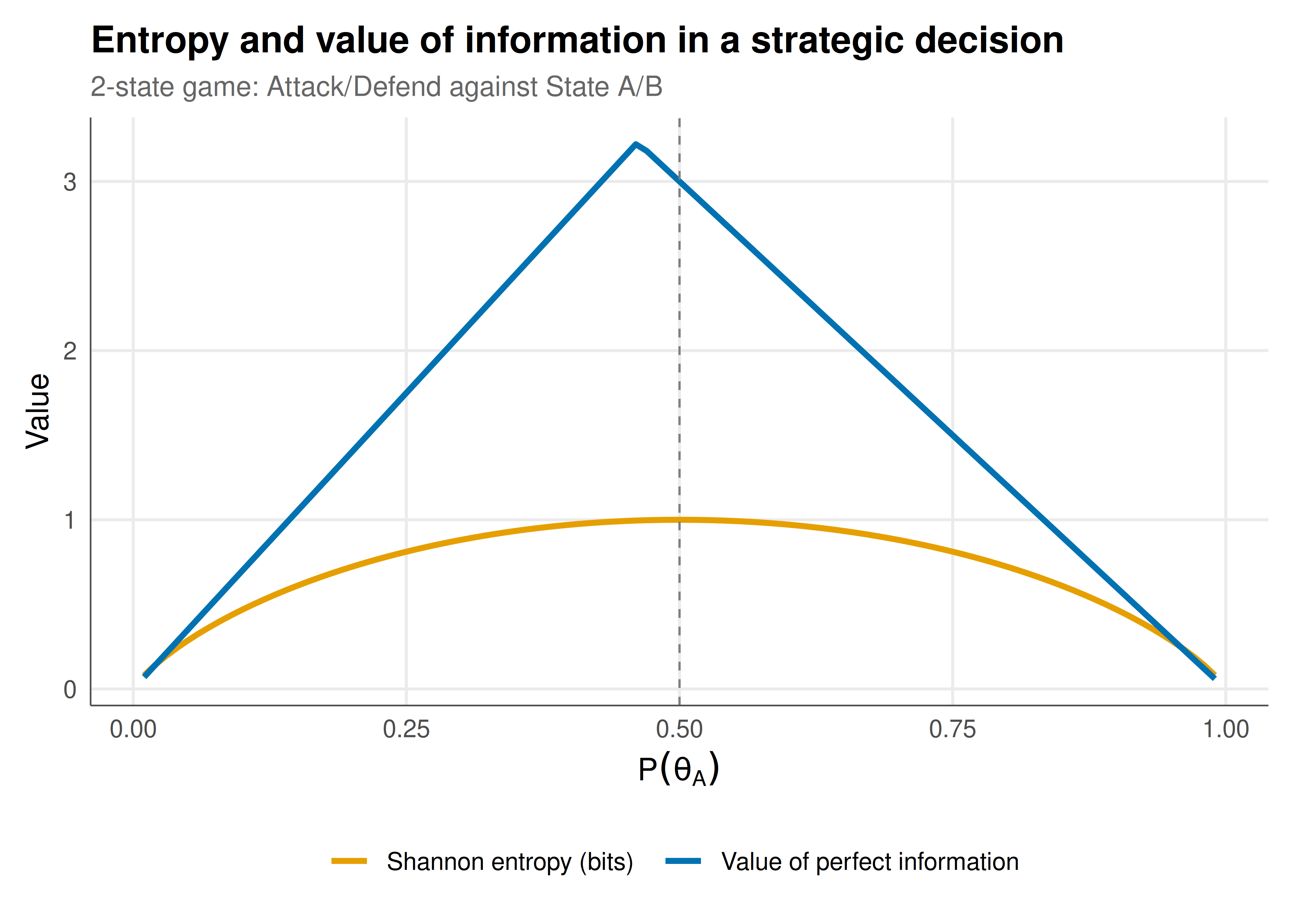
#| fig-cap: "Figure 1. Shannon entropy and value of perfect information as functions of the prior probability of State A in a 2-state, 2-action strategic decision. Entropy peaks at the uniform prior (p = 0.5); VPI peaks where the uninformed decision is most uncertain — the prior at which the optimal uninformed action switches. Okabe-Ito palette."
#| dev: [png, pdf]
#| fig-width: 7
#| fig-height: 5
#| dpi: 300
results_long <- results |>
pivot_longer(cols = c(entropy, vpi),
names_to = "measure",
values_to = "value") |>
mutate(measure = recode(measure,
"entropy" = "Shannon entropy (bits)",
"vpi" = "Value of perfect information"
))
p_entropy <- ggplot(results_long, aes(x = p_A, y = value, color = measure)) +
geom_line(linewidth = 1.1) +
geom_vline(xintercept = 0.5, linetype = "dashed", color = "grey50", linewidth = 0.4) +
scale_color_manual(values = c(
"Shannon entropy (bits)" = okabe_ito[1],
"Value of perfect information" = okabe_ito[5]
), name = NULL) +
labs(
title = "Entropy and value of information in a strategic decision",
subtitle = "2-state game: Attack/Defend against State A/B",
x = expression(P(theta[A])),
y = "Value"
) +
theme_publication()
p_entropy
```
## Interactive figure
```{r}
#| label: fig-entropy-vpi-interactive
# Build an interactive version with signal quality exploration
signal_qualities <- c(0.5, 0.6, 0.7, 0.8, 0.9, 1.0)
signal_results <- bind_rows(lapply(signal_qualities, function(q) {
tibble(
p_A = seq(0.01, 0.99, by = 0.01),
signal_quality = paste0("q = ", q),
entropy_reduction = mapply(function(pA) {
prior_h <- shannon_entropy(c(pA, 1 - pA))
# Signal with quality q: P(s_A | theta_A) = q
joint <- matrix(c(pA * q, pA * (1 - q),
(1 - pA) * (1 - q), (1 - pA) * q),
nrow = 2, byrow = TRUE)
cond_h <- conditional_entropy(joint)
prior_h - cond_h
}, p_A),
text = paste0("P(A) = ", round(p_A, 2),
"\nSignal quality: ", q,
"\nBits resolved: ", round(entropy_reduction, 3))
)
}))
p_signal <- ggplot(signal_results,
aes(x = p_A, y = entropy_reduction,
color = signal_quality, text = text)) +
geom_line(linewidth = 0.8) +
scale_color_manual(values = setNames(okabe_ito[1:6], unique(signal_results$signal_quality)),
name = "Signal quality") +
labs(
title = "Mutual information by signal quality",
subtitle = "Bits of uncertainty resolved for varying priors and signal accuracy",
x = expression(P(theta[A])),
y = "Mutual information (bits)"
) +
theme_publication()
ggplotly(p_signal, tooltip = "text") |>
config(displaylogo = FALSE,
modeBarButtonsToRemove = c("select2d", "lasso2d"))
```
## Interpretation
The relationship between entropy and the value of information reveals a fundamental asymmetry in strategic settings. While Shannon entropy is a symmetric function of the prior — maximised at the uniform distribution and decreasing toward both extremes — the value of perfect information is not symmetric in general. VPI peaks at the prior where the uninformed decision-maker is exactly indifferent between actions, the critical threshold where additional information tips the balance. Away from this threshold, even substantial uncertainty (high entropy) may have low value because the optimal action is robust to the remaining ambiguity. This distinction matters profoundly for mechanism design: a principal choosing what to reveal should focus not on maximising entropy reduction in the abstract, but on targeting the specific uncertainty that influences the agent's action choice. The signal quality analysis reinforces this: a noisy signal (low $q$) provides diminishing returns, and the mutual information curve shows that the marginal value of signal accuracy is highest near $q = 1$. In multi-player settings, information value can become negative — revealing your private information to an opponent may hurt you — breaking the single-agent guarantee that information is always beneficial. This fundamental tension drives much of the theory of strategic information revelation, cheap talk, and signalling games explored elsewhere in #equilibria.
## Extensions & related tutorials
- [Bayesian games and belief updating](../../bayesian-methods/bayesian-games-beliefs/) — where priors and signals shape equilibrium strategies.
- [Mechanism design fundamentals](../../mechanism-design/mechanism-design-intro/) — the principal designs what information is revealed.
- [The Prisoner's Dilemma — formal setup](../../classical-games/prisoners-dilemma-formal/) — a complete information benchmark.
- [Signalling games and pooling equilibria](../../information-theory/signalling-games/) — strategic information transmission.
- [Auction theory and information rents](../../auction-theory-deep-dive/first-price-auction/) — information asymmetry in competitive bidding.
## References
::: {#refs}
:::