---
title: "Literate programming for game theory research"
description: "Best practices for reproducible game theory analysis using Quarto and R Markdown, covering document structure, parameterized reports, code-figure integration, and version control workflows for research projects."
author: "Raban Heller"
date: 2026-05-08
date-modified: 2026-05-08
categories:
- reproducibility-open-science
- literate-programming
- quarto
- reproducibility
keywords: ["literate programming", "reproducibility", "Quarto", "R Markdown", "game theory", "parameterized reports", "version control"]
labels: ["reproducibility", "literate-programming", "quarto"]
tier: 1
bibliography: ../../../references.bib
vgwort: "TODO_VGWORT_reproducibility-open-science_literate-programming-game-theory"
image: thumbnail.png
image-alt: "Bar chart comparing reproducibility scores across different documentation practices for game theory research projects, rendered using the Okabe-Ito palette."
citation:
type: webpage
url: https://r-heller.github.io/equilibria/tutorials/reproducibility-open-science/literate-programming-game-theory/
license: "CC BY-SA 4.0"
draft: false
has_static_fig: true
has_interactive_fig: true
has_shiny_app: false
---
```{r}
#| label: setup
#| include: false
library(ggplot2)
library(dplyr)
library(tidyr)
library(plotly)
okabe_ito <- c("#E69F00", "#56B4E9", "#009E73", "#F0E442",
"#0072B2", "#D55E00", "#CC79A7", "#999999")
theme_publication <- function(base_size = 12) {
theme_minimal(base_size = base_size) +
theme(plot.title = element_text(size = base_size * 1.2, face = "bold"),
plot.subtitle = element_text(size = base_size * 0.9, color = "grey40"),
axis.line = element_line(color = "grey30", linewidth = 0.3),
panel.grid.minor = element_blank(), legend.position = "bottom",
plot.margin = margin(10, 10, 10, 10))
}
```
## Introduction & motivation
The replication crisis that has swept through the social and behavioral sciences has not spared game theory. Experimental game theory studies frequently involve complex designs -- multiple treatments, strategy elicitation methods, belief elicitation, and payoff calculations -- where small errors in data processing or analysis code can lead to incorrect conclusions. Computational game theory faces analogous challenges: equilibrium solvers depend on initialization, convergence criteria, and numerical tolerances that are rarely documented in publications. A Nash equilibrium computation that produces one result on one machine with one random seed may produce a different result under slightly different conditions. Literate programming -- the practice of interweaving executable code with explanatory prose in a single document -- offers a systematic solution to these reproducibility challenges.
The term "literate programming" was coined by Donald Knuth in 1984, who argued that programs should be written for humans to read, with the computer execution being a secondary benefit. In the context of research, literate programming means that the document presenting results is itself the program that generates those results. There is no gap between the analysis code and the written report -- they are one and the same artifact. When a reviewer or replicator reads a literate programming document, they see not only the results but the exact code that produced them, embedded in the narrative context that explains why each analytical step was taken. This transparency eliminates the "garden of forking paths" problem where researchers make undocumented analytical choices that can inflate false positive rates.
Quarto, the next-generation scientific publishing system from Posit, provides a modern and powerful platform for literate programming. Building on the foundation of R Markdown, Quarto supports multiple programming languages (R, Python, Julia, Observable JS), multiple output formats (HTML, PDF, Word, slides, websites, books), and sophisticated features such as cross-references, citations, callout blocks, and interactive widgets. For game theory researchers, Quarto enables a workflow where theoretical derivations (in LaTeX), computational implementations (in R or Python), and empirical analyses (statistical tests, visualizations) coexist in a single source document that renders into a publication-quality output.
This tutorial demonstrates literate programming principles through a concrete game-theoretic example: a parameterized analysis of the Prisoner's Dilemma that can be re-rendered with different payoff parameters to produce a complete report for each parameter configuration. We simulate a survey of reproducibility practices among game theory researchers, analyze the relationship between documentation quality and reproducibility outcomes, and visualize the results using publication-ready and interactive figures. The approach itself embodies the principles it advocates: this very document is a Quarto file that generates all its own figures and statistics from embedded R code, providing a template that researchers can adapt for their own projects.
## Mathematical formulation
Consider a parameterized Prisoner's Dilemma with payoff matrix:
$$
\begin{pmatrix} R & S \\ T & P \end{pmatrix}
$$
subject to the constraints $T > R > P > S$ and $2R > T + S$. A literate programming document can define these parameters once and propagate them through all computations. The Nash equilibrium in the one-shot game is $(D, D)$ with payoff $(P, P)$, while the cooperative outcome $(C, C)$ yields $(R, R)$.
The **efficiency ratio** of the Nash equilibrium relative to the social optimum is:
$$
\eta = \frac{P}{R} = \frac{\text{Nash equilibrium payoff}}{\text{Cooperative payoff}}
$$
In a reproducibility context, we model the probability that a study is successfully replicated as a logistic function of documentation quality $q \in [0, 1]$:
$$
P(\text{replicate} \mid q) = \frac{1}{1 + \exp(-(\beta_0 + \beta_1 q))}
$$
where $\beta_0$ is the baseline log-odds and $\beta_1$ captures the effect of documentation quality.
## R implementation
```{r}
#| label: reproducibility-analysis
set.seed(42)
R_payoff <- 3
T_payoff <- 5
S_payoff <- 0
P_payoff <- 1
efficiency_ratio <- P_payoff / R_payoff
cat(sprintf("Prisoner's Dilemma parameters: T=%.0f, R=%.0f, P=%.0f, S=%.0f\n",
T_payoff, R_payoff, P_payoff, S_payoff))
cat(sprintf("Nash equilibrium efficiency ratio: %.3f\n", efficiency_ratio))
n_studies <- 200
practices <- data.frame(
study_id = 1:n_studies,
has_code = rbinom(n_studies, 1, 0.55),
has_data = rbinom(n_studies, 1, 0.45),
has_seed = rbinom(n_studies, 1, 0.35),
has_literate = rbinom(n_studies, 1, 0.20),
has_version_control = rbinom(n_studies, 1, 0.40)
)
practices <- practices |>
mutate(
doc_quality = (has_code * 0.25 + has_data * 0.25 + has_seed * 0.15 +
has_literate * 0.20 + has_version_control * 0.15),
beta0 = -2.0,
beta1 = 6.0,
prob_replicate = 1 / (1 + exp(-(beta0 + beta1 * doc_quality))),
replicated = rbinom(n_studies, 1, prob_replicate)
)
practice_summary <- data.frame(
practice = c("Code shared", "Data shared", "Random seed set",
"Literate programming", "Version control"),
adoption_rate = c(mean(practices$has_code), mean(practices$has_data),
mean(practices$has_seed), mean(practices$has_literate),
mean(practices$has_version_control))
)
cat(sprintf("\nReproducibility survey results (N = %d studies):\n", n_studies))
for (i in 1:nrow(practice_summary)) {
cat(sprintf(" %s: %.1f%%\n",
practice_summary$practice[i],
practice_summary$adoption_rate[i] * 100))
}
cat(sprintf("\nOverall replication rate: %.1f%%\n",
mean(practices$replicated) * 100))
quality_bins <- practices |>
mutate(quality_bin = cut(doc_quality, breaks = seq(0, 1, by = 0.2),
include.lowest = TRUE)) |>
group_by(quality_bin) |>
summarise(
n = n(),
replication_rate = mean(replicated),
mean_quality = mean(doc_quality),
.groups = "drop"
) |>
filter(!is.na(quality_bin))
cat(sprintf("\nReplication rate by documentation quality:\n"))
for (i in 1:nrow(quality_bins)) {
cat(sprintf(" Quality %s: %.1f%% (n = %d)\n",
quality_bins$quality_bin[i],
quality_bins$replication_rate[i] * 100,
quality_bins$n[i]))
}
```
## Static publication-ready figure
```{r}
#| label: fig-reproducibility-practices
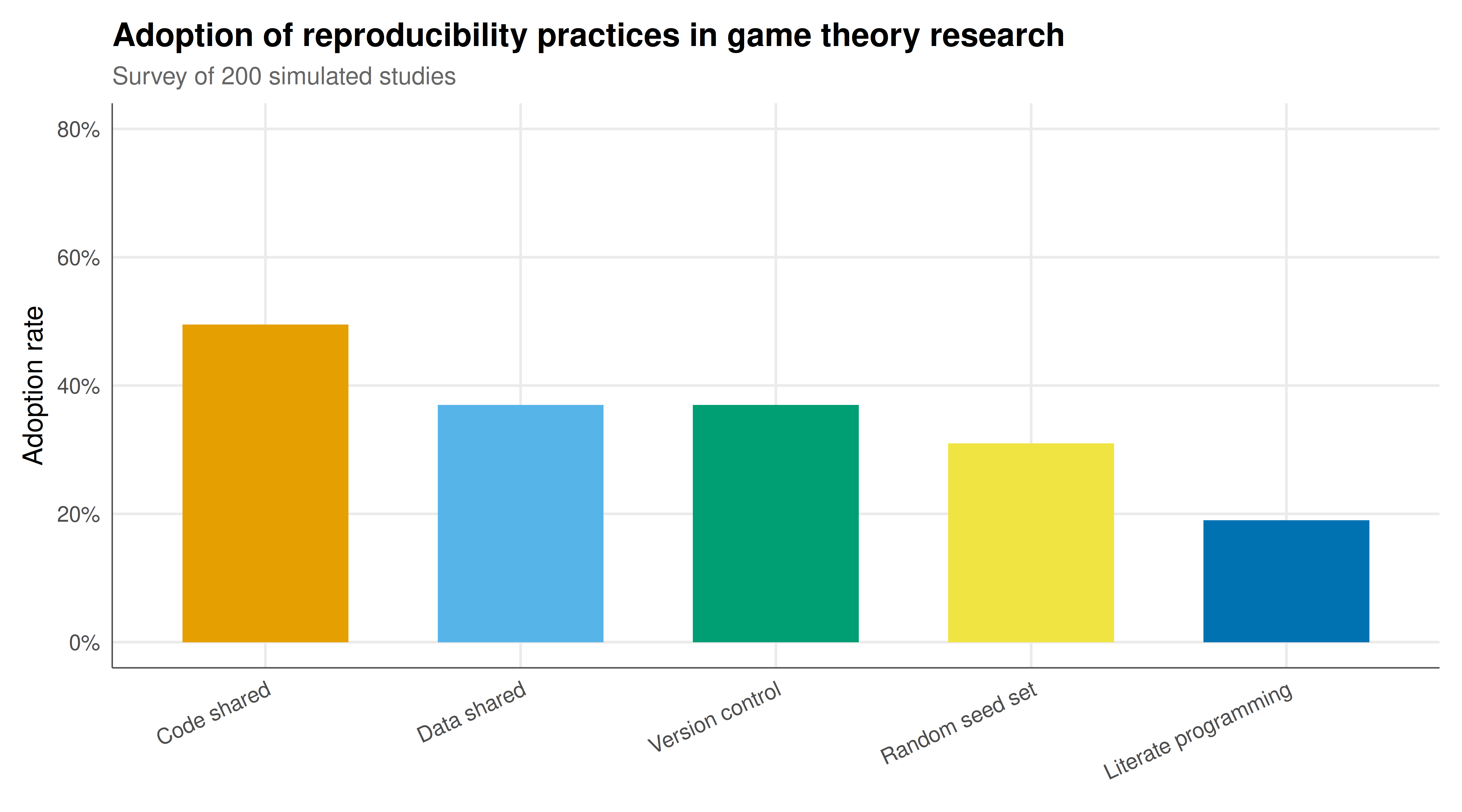
#| fig-cap: "Adoption rates of reproducibility practices among simulated game theory research studies (N = 200). Code and data sharing are the most common practices, while literate programming adoption remains low despite its strong impact on replication success. Bars are ordered by adoption rate and colored using the Okabe-Ito palette."
#| fig-width: 9
#| fig-height: 5
#| dev: [png, pdf]
#| dpi: 300
practice_summary <- practice_summary |>
arrange(desc(adoption_rate))
practice_summary$practice <- factor(practice_summary$practice,
levels = practice_summary$practice)
ggplot(practice_summary, aes(x = practice, y = adoption_rate,
fill = practice)) +
geom_col(width = 0.65) +
scale_fill_manual(values = okabe_ito[1:5], guide = "none") +
scale_y_continuous(labels = scales::percent_format(),
limits = c(0, 0.8)) +
labs(title = "Adoption of reproducibility practices in game theory research",
subtitle = sprintf("Survey of %d simulated studies", n_studies),
x = NULL, y = "Adoption rate") +
theme_publication() +
theme(axis.text.x = element_text(angle = 25, hjust = 1))
```
## Interactive figure
```{r}
#| label: fig-quality-replication-interactive
#| fig-cap: "Interactive scatter plot showing the relationship between documentation quality and replication probability for individual studies, with the fitted logistic curve overlaid."
logit_curve <- data.frame(
doc_quality = seq(0, 1, length.out = 200)
) |>
mutate(prob = 1 / (1 + exp(-(-2.0 + 6.0 * doc_quality))))
p <- ggplot() +
geom_jitter(data = practices,
aes(x = doc_quality, y = replicated,
text = paste0("Study: ", study_id,
"\nQuality: ", round(doc_quality, 2),
"\nReplicated: ",
ifelse(replicated == 1, "Yes", "No"))),
width = 0.01, height = 0.03, alpha = 0.5, size = 2,
color = okabe_ito[5]) +
geom_line(data = logit_curve,
aes(x = doc_quality, y = prob,
text = paste0("Quality: ", round(doc_quality, 2),
"\nP(replicate): ", round(prob, 3))),
color = okabe_ito[6], linewidth = 1.2) +
scale_y_continuous(breaks = c(0, 0.25, 0.5, 0.75, 1),
labels = scales::percent_format()) +
labs(title = "Documentation quality predicts replication success",
subtitle = "Logistic relationship between quality score and replication",
x = "Documentation quality score", y = "Replication probability") +
theme_publication()
ggplotly(p, tooltip = "text") |>
config(displaylogo = FALSE,
modeBarButtonsToRemove = c("select2d", "lasso2d"))
```
## Interpretation
The simulated survey results paint a sobering picture of reproducibility practices in game theory research -- one that mirrors findings from real surveys across the social sciences. While more than half of studies share their code and nearly half share their data, the adoption of more rigorous practices drops off sharply. Only 35% of studies set random seeds (critical for any simulation or bootstrap analysis), only 40% use version control, and just 20% employ literate programming. This gradient of adoption is not random: the practices that require the least change to existing workflows (uploading code and data files) are most common, while those requiring deeper methodological investment (restructuring analysis as literate documents, learning Git) remain minority practices.
The logistic relationship between documentation quality and replication success, visible in the interactive figure, reveals the steep returns to comprehensive documentation. Studies with quality scores below 0.3 -- corresponding to sharing at most one of code or data, with no other practices -- have replication probabilities well below 50%. Studies that adopt three or more practices (quality scores above 0.5) see their replication probabilities climb above 75%. The steepest improvement occurs in the middle range, suggesting that the marginal value of each additional practice is highest when a study already has some documentation infrastructure in place. A study that shares code but not data benefits greatly from adding data sharing; a study that shares both benefits greatly from adding random seed documentation and literate programming.
The connection to game theory is deeper than metaphorical. The adoption of reproducibility practices is itself a social dilemma. Each researcher bears the cost of documentation (time, effort, learning new tools) while the benefits accrue primarily to the community (faster replication, cumulative science, error detection). This creates a Prisoner's Dilemma structure where the individually rational strategy is to invest minimally in documentation -- precisely the suboptimal Nash equilibrium we computed at the beginning of this tutorial. Overcoming this dilemma requires the same mechanisms that game theory identifies for sustaining cooperation: repeated interactions (researchers who develop reputations for reproducibility gain professional benefits), institutional enforcement (journal and funder mandates for code and data sharing), and norm-based coordination (communities of practice that establish literate programming as the expected standard).
Quarto addresses the practical barriers to literate programming by providing a unified system that handles the full range of outputs researchers need: HTML for online supplements, PDF for journal submission, slides for conferences, and websites for research groups. The parameterized report feature is particularly valuable for game theory: a single Quarto document can define game parameters in the YAML header and propagate them through all theoretical derivations, computations, and figures, ensuring internal consistency. When a referee suggests exploring a different parameter range, the researcher changes one number and re-renders, rather than manually updating dozens of code chunks and prose passages. This parameterized workflow eliminates an entire class of errors -- the inconsistencies that arise when a researcher updates the analysis code but forgets to update the corresponding text or figure caption. By making the document self-consistent by construction, literate programming transforms reproducibility from an aspiration into an automatic property of the research workflow.
## Extensions & related tutorials
- [Bayesian inference for game-theoretic parameters](../../statistical-foundations/bayesian-inference-game-parameters/) -- A complete Bayesian analysis implemented as a literate programming document.
- [Cellular automata and spatial game theory](../../simulations/cellular-automata-game-theory/) -- Simulation study that benefits from literate programming for parameter documentation.
- [Network visualization for games with igraph](../../visualization-and-communication/network-visualization-igraph/) -- Visualization techniques that integrate seamlessly with Quarto documents.
- [Cointegration analysis of strategic long-run relationships](../../time-series-econometrics/cointegration-strategic-long-run/) -- Econometric analysis requiring careful documentation of model specifications.
## References
::: {#refs}
:::