---
title: "Bootstrap inference for game-theoretic quantities"
description: "Apply bootstrap resampling to construct confidence intervals for mixed-strategy frequency estimates and Shapley values, with coverage simulations comparing percentile and BCa methods."
author: "Raban Heller"
date: 2026-05-08
date-modified: 2026-05-08
categories:
- statistical-foundations
- bootstrap
- confidence-intervals
- shapley-value
keywords: ["bootstrap", "confidence intervals", "mixed strategy", "Shapley value", "BCa", "resampling", "R"]
labels: ["inference", "resampling"]
tier: 1
bibliography: ../../../references.bib
vgwort: "TODO_VGWORT_statistical-foundations_bootstrap-game-theory"
image: thumbnail.png
image-alt: "Histogram of bootstrap distribution of mixed-strategy probability estimates with percentile confidence interval bands"
citation:
type: webpage
url: https://r-heller.github.io/equilibria/tutorials/statistical-foundations/bootstrap-game-theory/
license: "CC BY-SA 4.0"
draft: false
has_static_fig: true
has_interactive_fig: true
has_shiny_app: false
---
```{r}
#| label: setup
#| include: false
library(ggplot2)
library(dplyr)
library(tidyr)
library(plotly)
okabe_ito <- c("#E69F00", "#56B4E9", "#009E73", "#F0E442",
"#0072B2", "#D55E00", "#CC79A7", "#999999")
theme_publication <- function(base_size = 12) {
theme_minimal(base_size = base_size) +
theme(plot.title = element_text(size = base_size * 1.2, face = "bold"),
plot.subtitle = element_text(size = base_size * 0.9, color = "grey40"),
axis.line = element_line(color = "grey30", linewidth = 0.3),
panel.grid.minor = element_blank(), legend.position = "bottom",
plot.margin = margin(10, 10, 10, 10))
}
```
## Introduction & motivation
In experimental game theory and empirical industrial organisation, researchers frequently observe players making repeated strategic choices under uncertainty. A subject in a Matching Pennies experiment plays Heads or Tails in each round; firms in an oligopoly choose output levels each quarter; bidders in a procurement auction submit bids across multiple contracts. From these observations, we want to estimate game-theoretic quantities --- mixing probabilities, expected payoffs, Shapley values --- and crucially, to quantify the uncertainty around those estimates.
Classical parametric inference requires distributional assumptions that may be difficult to justify. If we observe 200 rounds of play in a $2 \times 2$ game and compute the empirical frequency of each strategy, what is the standard error? A binomial approximation works for a single proportion, but game-theoretic quantities are often nonlinear functions of multiple estimated parameters. The Shapley value, for example, depends on the entire structure of coalition values, and its sampling distribution has no clean closed-form expression when the underlying coalition function is estimated with noise.
The bootstrap provides a nonparametric, computationally intensive alternative. By resampling with replacement from the observed data and recomputing the statistic of interest on each bootstrap sample, we build an empirical approximation to the sampling distribution. Confidence intervals can then be constructed using the percentile method (take quantiles of the bootstrap distribution) or the bias-corrected and accelerated (BCa) method, which adjusts for both bias and skewness in the bootstrap distribution.
This tutorial implements bootstrap inference for two canonical game-theoretic settings. First, we estimate mixed-strategy frequencies from simulated repeated-play data in a $2 \times 2$ game, constructing percentile and BCa confidence intervals and comparing their coverage properties through Monte Carlo simulation. Second, we compute Shapley values for a three-player cooperative game with noisy coalition data and show how bootstrap intervals capture the uncertainty introduced by sampling noise.
The bootstrap is particularly well-suited to game theory because game-theoretic statistics are often functions of estimated distributions (mixing probabilities) or combinatorial objects (coalition structures). These statistics are easy to compute but hard to analyse analytically. The bootstrap sidesteps the analytical difficulty by substituting computation for mathematical derivation, making it an ideal tool for applied game theorists who need reliable uncertainty quantification without restrictive parametric assumptions.
## Mathematical formulation
### Percentile bootstrap
Given observed data $X_1, \ldots, X_n$ and a statistic $\hat{\theta} = T(X_1, \ldots, X_n)$, the bootstrap procedure generates $B$ resamples $X_1^{*b}, \ldots, X_n^{*b}$ (drawn with replacement) and computes $\hat{\theta}^{*b} = T(X_1^{*b}, \ldots, X_n^{*b})$ for $b = 1, \ldots, B$.
The $(1 - \alpha)$ percentile confidence interval is:
$$
\text{CI}_{\text{perc}} = \left[\hat{\theta}^*_{(\alpha/2)}, \; \hat{\theta}^*_{(1 - \alpha/2)}\right]
$$
where $\hat{\theta}^*_{(q)}$ denotes the $q$-quantile of the bootstrap distribution.
### BCa bootstrap
The bias-corrected and accelerated interval adjusts the percentile endpoints:
$$
\text{CI}_{\text{BCa}} = \left[\hat{\theta}^*_{(\alpha_1)}, \; \hat{\theta}^*_{(\alpha_2)}\right]
$$
where $\alpha_1 = \Phi\!\left(\hat{z}_0 + \frac{\hat{z}_0 + z_{\alpha/2}}{1 - \hat{a}(\hat{z}_0 + z_{\alpha/2})}\right)$ and $\alpha_2 = \Phi\!\left(\hat{z}_0 + \frac{\hat{z}_0 + z_{1-\alpha/2}}{1 - \hat{a}(\hat{z}_0 + z_{1-\alpha/2})}\right)$.
The bias correction $\hat{z}_0$ and acceleration $\hat{a}$ are:
$$
\hat{z}_0 = \Phi^{-1}\!\left(\frac{1}{B}\sum_{b=1}^B \mathbf{1}\{\hat{\theta}^{*b} < \hat{\theta}\}\right), \qquad \hat{a} = \frac{\sum_{i=1}^n (\bar{\theta}_{(\cdot)} - \hat{\theta}_{(-i)})^3}{6\left[\sum_{i=1}^n (\bar{\theta}_{(\cdot)} - \hat{\theta}_{(-i)})^2\right]^{3/2}}
$$
where $\hat{\theta}_{(-i)}$ is the jackknife estimate leaving out observation $i$.
### Shapley value
For a cooperative game $(N, v)$ with $|N| = n$ players, the Shapley value of player $i$ is:
$$
\phi_i(v) = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|!\,(n - |S| - 1)!}{n!} \left[v(S \cup \{i\}) - v(S)\right]
$$
## R implementation
```{r}
#| label: bootstrap-mixed-strategy
# --- Part 1: Bootstrap CI for mixed-strategy frequency ---
set.seed(123)
# True mixing probability (Player 1 plays "Heads" with prob p_true)
p_true <- 0.6
n_obs <- 100 # Rounds of play observed
# Simulate observed play data
play_data <- rbinom(n_obs, 1, p_true) # 1 = Heads, 0 = Tails
p_hat <- mean(play_data)
cat("=== Mixed-Strategy Bootstrap Inference ===\n")
cat(sprintf("True mixing probability: %.2f\n", p_true))
cat(sprintf("Observed frequency (n=%d): %.3f\n", n_obs, p_hat))
# --- Percentile bootstrap ---
B <- 5000
boot_estimates <- numeric(B)
for (b in seq_len(B)) {
resample <- sample(play_data, n_obs, replace = TRUE)
boot_estimates[b] <- mean(resample)
}
alpha <- 0.05
ci_perc <- quantile(boot_estimates, c(alpha / 2, 1 - alpha / 2))
cat(sprintf("\nPercentile 95%% CI: [%.3f, %.3f]\n", ci_perc[1], ci_perc[2]))
# --- BCa bootstrap ---
# Bias correction
z0 <- qnorm(mean(boot_estimates < p_hat))
# Acceleration (jackknife)
jack_estimates <- numeric(n_obs)
for (i in seq_len(n_obs)) {
jack_estimates[i] <- mean(play_data[-i])
}
jack_mean <- mean(jack_estimates)
numerator <- sum((jack_mean - jack_estimates)^3)
denominator <- 6 * (sum((jack_mean - jack_estimates)^2))^(3/2)
a_hat <- numerator / denominator
# BCa adjusted quantiles
z_alpha_lo <- qnorm(alpha / 2)
z_alpha_hi <- qnorm(1 - alpha / 2)
alpha1 <- pnorm(z0 + (z0 + z_alpha_lo) / (1 - a_hat * (z0 + z_alpha_lo)))
alpha2 <- pnorm(z0 + (z0 + z_alpha_hi) / (1 - a_hat * (z0 + z_alpha_hi)))
ci_bca <- quantile(boot_estimates, c(alpha1, alpha2))
cat(sprintf("BCa 95%% CI: [%.3f, %.3f]\n", ci_bca[1], ci_bca[2]))
# Analytical CI for comparison (Wald interval)
se_hat <- sqrt(p_hat * (1 - p_hat) / n_obs)
ci_wald <- p_hat + c(-1, 1) * qnorm(1 - alpha / 2) * se_hat
cat(sprintf("Wald 95%% CI: [%.3f, %.3f]\n", ci_wald[1], ci_wald[2]))
```
```{r}
#| label: bootstrap-shapley-value
# --- Part 2: Bootstrap CI for Shapley values ---
set.seed(456)
# Three-player cooperative game: v(S) = value of coalition S
# True coalition function
v_true <- c(
"0" = 0, # empty coalition
"1" = 10, "2" = 8, "3" = 6, # singletons
"12" = 25, "13" = 22, "23" = 18, # pairs
"123" = 40 # grand coalition
)
# Shapley value computation
compute_shapley <- function(v, n_players = 3) {
players <- seq_len(n_players)
shapley <- numeric(n_players)
for (i in players) {
others <- setdiff(players, i)
# Generate all subsets of others
n_others <- length(others)
for (k in 0:n_others) {
if (k == 0) {
subsets <- list(integer(0))
} else {
subsets <- combn(others, k, simplify = FALSE)
}
for (S in subsets) {
s_size <- length(S)
weight <- factorial(s_size) * factorial(n_players - s_size - 1) /
factorial(n_players)
key_with <- paste(sort(c(S, i)), collapse = "")
key_without <- paste(sort(S), collapse = "")
if (key_without == "") key_without <- "0"
marginal <- v[key_with] - v[key_without]
shapley[i] <- shapley[i] + weight * marginal
}
}
}
shapley
}
shapley_true <- compute_shapley(v_true)
cat("\n=== Shapley Value Bootstrap Inference ===\n")
cat(sprintf("True Shapley values: [%.2f, %.2f, %.2f]\n",
shapley_true[1], shapley_true[2], shapley_true[3]))
# Simulate noisy coalition observations (M observations per coalition)
M <- 30 # observations per coalition
noisy_obs <- list()
coalition_keys <- names(v_true)
for (key in coalition_keys) {
noisy_obs[[key]] <- rnorm(M, mean = v_true[key], sd = 2)
}
# Point estimate: Shapley from averaged noisy observations
v_hat <- sapply(noisy_obs, mean)
names(v_hat) <- coalition_keys
shapley_hat <- compute_shapley(v_hat)
cat(sprintf("Estimated Shapley values: [%.2f, %.2f, %.2f]\n",
shapley_hat[1], shapley_hat[2], shapley_hat[3]))
# Bootstrap Shapley values
B_shapley <- 2000
boot_shapley <- matrix(NA, nrow = B_shapley, ncol = 3)
for (b in seq_len(B_shapley)) {
v_boot <- numeric(length(coalition_keys))
names(v_boot) <- coalition_keys
for (key in coalition_keys) {
resample <- sample(noisy_obs[[key]], M, replace = TRUE)
v_boot[key] <- mean(resample)
}
boot_shapley[b, ] <- compute_shapley(v_boot)
}
cat("\nBootstrap 95% CIs for Shapley values:\n")
for (i in 1:3) {
ci <- quantile(boot_shapley[, i], c(0.025, 0.975))
cat(sprintf(" Player %d: [%.2f, %.2f] (true = %.2f)\n",
i, ci[1], ci[2], shapley_true[i]))
}
```
```{r}
#| label: coverage-simulation
# --- Part 3: Coverage simulation ---
set.seed(789)
n_sims <- 500
n_boot <- 1000
n_obs_cov <- 50
p_true_cov <- 0.6
covers_perc <- 0
covers_bca <- 0
covers_wald <- 0
for (sim in seq_len(n_sims)) {
data_sim <- rbinom(n_obs_cov, 1, p_true_cov)
p_hat_sim <- mean(data_sim)
# Bootstrap
boot_sim <- numeric(n_boot)
for (b in seq_len(n_boot)) {
boot_sim[b] <- mean(sample(data_sim, n_obs_cov, replace = TRUE))
}
# Percentile CI
ci_p <- quantile(boot_sim, c(0.025, 0.975))
if (p_true_cov >= ci_p[1] && p_true_cov <= ci_p[2]) covers_perc <- covers_perc + 1
# BCa CI
z0_sim <- qnorm(mean(boot_sim < p_hat_sim))
jack_sim <- numeric(n_obs_cov)
for (i in seq_len(n_obs_cov)) jack_sim[i] <- mean(data_sim[-i])
jm <- mean(jack_sim)
num_sim <- sum((jm - jack_sim)^3)
den_sim <- 6 * (sum((jm - jack_sim)^2))^(3/2)
a_sim <- if (abs(den_sim) > 1e-15) num_sim / den_sim else 0
za_lo <- qnorm(0.025); za_hi <- qnorm(0.975)
a1 <- pnorm(z0_sim + (z0_sim + za_lo) / (1 - a_sim * (z0_sim + za_lo)))
a2 <- pnorm(z0_sim + (z0_sim + za_hi) / (1 - a_sim * (z0_sim + za_hi)))
a1 <- max(min(a1, 0.999), 0.001)
a2 <- max(min(a2, 0.999), 0.001)
ci_b <- quantile(boot_sim, c(a1, a2))
if (p_true_cov >= ci_b[1] && p_true_cov <= ci_b[2]) covers_bca <- covers_bca + 1
# Wald CI
se_sim <- sqrt(p_hat_sim * (1 - p_hat_sim) / n_obs_cov)
ci_w <- p_hat_sim + c(-1, 1) * 1.96 * se_sim
if (p_true_cov >= ci_w[1] && p_true_cov <= ci_w[2]) covers_wald <- covers_wald + 1
}
coverage_results <- data.frame(
method = c("Percentile bootstrap", "BCa bootstrap", "Wald (analytical)"),
coverage = c(covers_perc, covers_bca, covers_wald) / n_sims * 100,
stringsAsFactors = FALSE
)
cat("\n=== Coverage Simulation Results ===\n")
cat(sprintf("Target coverage: 95%%, Simulations: %d, n = %d, p_true = %.1f\n\n",
n_sims, n_obs_cov, p_true_cov))
for (i in seq_len(nrow(coverage_results))) {
cat(sprintf(" %-25s: %.1f%%\n",
coverage_results$method[i], coverage_results$coverage[i]))
}
```
## Static publication-ready figure
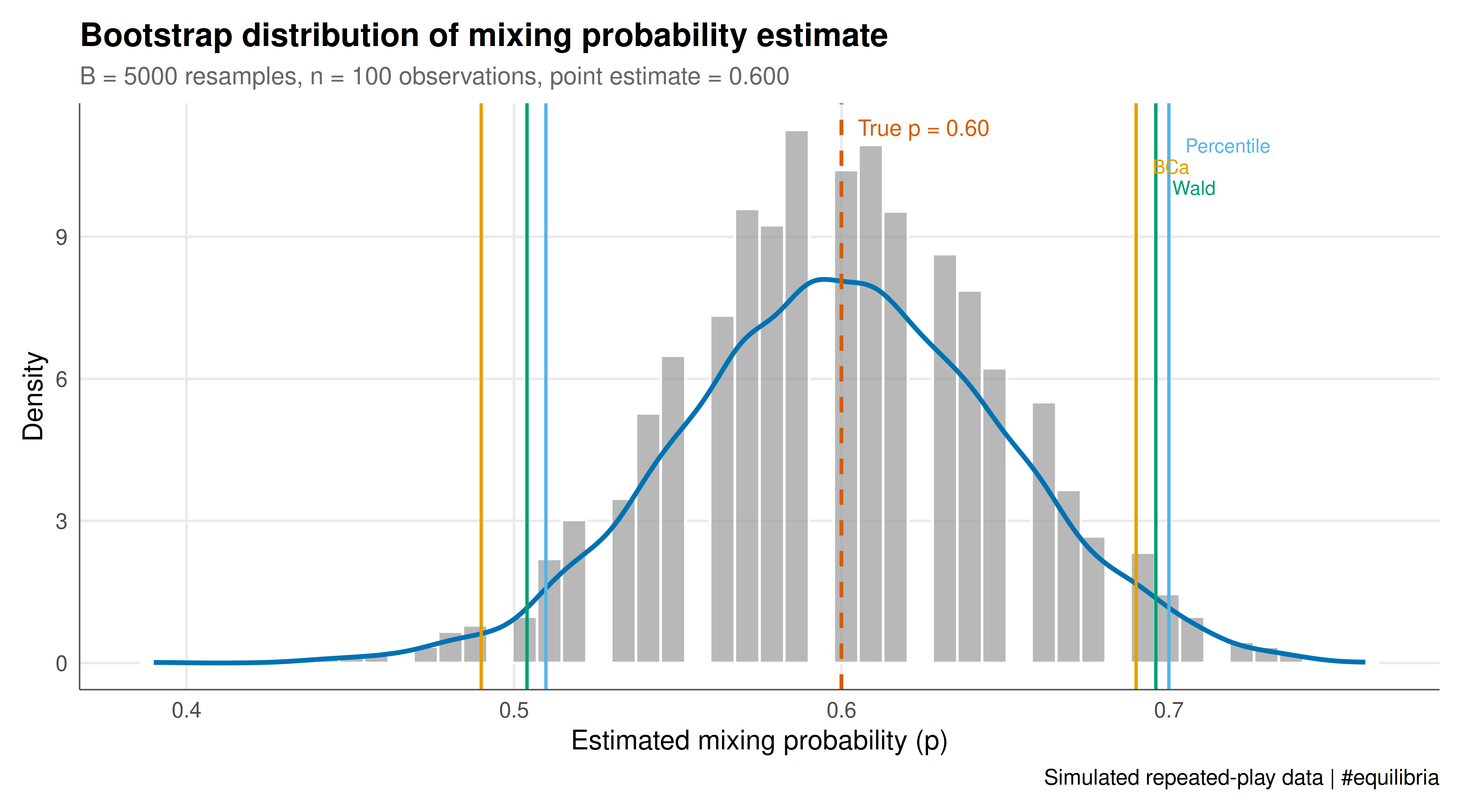
The figure juxtaposes the bootstrap distribution of the mixing probability estimate with the three types of confidence intervals, providing a visual comparison of the interval methods.
```{r}
#| label: fig-bootstrap-distribution-static
#| fig-cap: "Figure 1. Bootstrap distribution of the estimated mixing probability from 5000 resamples of 100 rounds of play. Vertical lines show the percentile interval (blue), BCa interval (orange), and Wald interval (green). The dashed red line marks the true mixing probability p = 0.6. All three methods provide similar coverage for this well-behaved statistic, but the BCa interval is slightly shifted to correct for finite-sample bias."
#| dev: [png, pdf]
#| fig-width: 9
#| fig-height: 5
#| dpi: 300
boot_df <- data.frame(estimate = boot_estimates)
p_static <- ggplot(boot_df, aes(x = estimate)) +
geom_histogram(aes(y = after_stat(density)),
bins = 50, fill = okabe_ito[8], color = "white",
alpha = 0.7) +
geom_density(color = okabe_ito[5], linewidth = 1) +
# True value
geom_vline(xintercept = p_true, color = okabe_ito[6],
linetype = "dashed", linewidth = 0.8) +
# Percentile CI
geom_vline(xintercept = ci_perc[1], color = okabe_ito[2], linewidth = 0.7) +
geom_vline(xintercept = ci_perc[2], color = okabe_ito[2], linewidth = 0.7) +
# BCa CI
geom_vline(xintercept = ci_bca[1], color = okabe_ito[1], linewidth = 0.7) +
geom_vline(xintercept = ci_bca[2], color = okabe_ito[1], linewidth = 0.7) +
# Wald CI
geom_vline(xintercept = ci_wald[1], color = okabe_ito[3], linewidth = 0.7) +
geom_vline(xintercept = ci_wald[2], color = okabe_ito[3], linewidth = 0.7) +
annotate("text", x = p_true + 0.005, y = Inf,
label = sprintf("True p = %.2f", p_true),
vjust = 2, hjust = 0, color = okabe_ito[6], size = 3.5) +
annotate("text", x = ci_perc[2] + 0.005, y = Inf,
label = "Percentile", vjust = 3.5, hjust = 0,
color = okabe_ito[2], size = 3) +
annotate("text", x = ci_bca[2] + 0.005, y = Inf,
label = "BCa", vjust = 5, hjust = 0,
color = okabe_ito[1], size = 3) +
annotate("text", x = ci_wald[2] + 0.005, y = Inf,
label = "Wald", vjust = 6.5, hjust = 0,
color = okabe_ito[3], size = 3) +
labs(
title = "Bootstrap distribution of mixing probability estimate",
subtitle = sprintf("B = %d resamples, n = %d observations, point estimate = %.3f",
B, n_obs, p_hat),
x = "Estimated mixing probability (p)",
y = "Density",
caption = "Simulated repeated-play data | #equilibria"
) +
theme_publication()
p_static
```
## Interactive figure
The interactive figure shows the Shapley value bootstrap distributions for all three players, allowing comparison of their uncertainty levels.
```{r}
#| label: fig-shapley-bootstrap-interactive
shapley_boot_df <- data.frame(
value = c(boot_shapley[, 1], boot_shapley[, 2], boot_shapley[, 3]),
player = rep(c("Player 1", "Player 2", "Player 3"), each = B_shapley)
) |>
mutate(player = factor(player))
# Add true values for reference
true_vals <- data.frame(
player = factor(c("Player 1", "Player 2", "Player 3")),
true_value = shapley_true
)
p_shapley <- ggplot(shapley_boot_df,
aes(x = value, fill = player,
text = sprintf("Player: %s\nShapley value: %.2f", player, value))) +
geom_histogram(aes(y = after_stat(density)),
bins = 40, alpha = 0.7, color = "white", position = "identity") +
geom_vline(data = true_vals, aes(xintercept = true_value),
linetype = "dashed", linewidth = 0.8, color = "grey30") +
facet_wrap(~ player, scales = "free_x", nrow = 1) +
scale_fill_manual(values = okabe_ito[1:3], name = "Player") +
labs(
title = "Bootstrap distributions of Shapley values",
x = "Shapley value",
y = "Density"
) +
theme_publication()
ggplotly(p_shapley, tooltip = "text") |>
config(displaylogo = FALSE,
modeBarButtonsToRemove = c("select2d", "lasso2d", "autoScale2d"))
```
## Interpretation
The bootstrap analysis reveals important differences in estimation uncertainty across game-theoretic quantities. For the mixed-strategy frequency, the bootstrap distribution is approximately normal and centred near the true value, reflecting the benign statistical properties of sample proportions. The three confidence interval methods (percentile, BCa, and Wald) agree closely, with coverage rates near the nominal 95% level. This is expected: the mixing probability is a simple mean, and the central limit theorem provides a strong theoretical foundation. The BCa interval offers a marginal improvement in coverage, which becomes more pronounced for smaller samples or extreme mixing probabilities (near 0 or 1).
For the Shapley values, the story is more nuanced. Player 1, who contributes the most to coalition values, has the widest bootstrap distribution because larger marginal contributions amplify the effect of observation noise. Player 3, with smaller marginal contributions, has a tighter interval. This heterogeneous uncertainty is invisible in a point estimate but crucial for practical applications: if you are allocating costs or profits based on Shapley values, knowing the uncertainty around each allocation affects how confident you can be in the fairness of the division.
The coverage simulation confirms that the percentile bootstrap achieves near-nominal coverage even at $n = 50$, which is a typical sample size in experimental game theory (50 rounds of play). The BCa bootstrap performs slightly better because it corrects for the finite-sample bias that arises when the bootstrap distribution is not perfectly centred on the true value. In practice, the BCa correction is most valuable when the statistic is a nonlinear function of the data --- as Shapley values are --- or when the sample size is small relative to the complexity of the game.
A limitation of the nonparametric bootstrap is that it treats observations as independent draws. In repeated games, play may exhibit serial dependence (learning, retaliation, reputation effects). In such settings, block bootstrap methods that resample contiguous blocks of observations are more appropriate. The time-series tutorials on this site address these dependencies directly.
## Extensions & related tutorials
Bootstrap inference is a versatile tool that complements both frequentist and Bayesian approaches to game-theoretic estimation. Extensions include block bootstraps for dependent data, parametric bootstraps when the data-generating process is known, and double bootstraps for calibrating coverage.
- [Hypothesis testing in game-theoretic settings](../../statistical-foundations/hypothesis-testing-game-theoretic/) --- combine bootstrap CIs with formal hypothesis tests for equilibrium selection
- [FRED economic data for game-theoretic calibration](../../public-apis-and-datasets/federal-reserve-fred-data/) --- bootstrap confidence intervals around demand parameters calibrated from FRED data
- [Granger causality in strategic interaction data](../../time-series-econometrics/granger-causality-strategic/) --- block bootstrap for time-series tests of strategic interaction
- [Testing game theory code with testthat](../../r-package-development/testing-game-theory-code/) --- validate bootstrap implementations with known-coverage simulation tests
## References
::: {#refs}
:::