---
title: "Privacy as a game --- strategic information disclosure"
description: "Model privacy decisions as games between users and data collectors, analyse the privacy paradox, simulate equilibrium disclosure under different regulation regimes, and explore mechanism design for truthful privacy-preference elicitation."
author: "Raban Heller"
date: 2026-05-08
date-modified: 2026-05-08
categories:
- ethics-applications
- privacy
- mechanism-design
- regulation
keywords: ["privacy", "game theory", "information disclosure", "privacy paradox", "GDPR", "mechanism design", "regulation", "R"]
labels: ["ethics", "applications"]
tier: 1
bibliography: ../../../references.bib
vgwort: "TODO_VGWORT_ethics-applications_privacy-game-theory"
image: thumbnail.png
image-alt: "Line plot comparing equilibrium disclosure levels across regulation regimes with welfare trade-off shading"
citation:
type: webpage
url: https://r-heller.github.io/equilibria/tutorials/ethics-applications/privacy-game-theory/
license: "CC BY-SA 4.0"
draft: false
has_static_fig: true
has_interactive_fig: true
has_shiny_app: false
framework: "consequentialism"
---
```{r}
#| label: setup
#| include: false
library(ggplot2)
library(dplyr)
library(tidyr)
library(plotly)
okabe_ito <- c("#E69F00", "#56B4E9", "#009E73", "#F0E442",
"#0072B2", "#D55E00", "#CC79A7", "#999999")
theme_publication <- function(base_size = 12) {
theme_minimal(base_size = base_size) +
theme(plot.title = element_text(size = base_size * 1.2, face = "bold"),
plot.subtitle = element_text(size = base_size * 0.9, color = "grey40"),
axis.line = element_line(color = "grey30", linewidth = 0.3),
panel.grid.minor = element_blank(), legend.position = "bottom",
plot.margin = margin(10, 10, 10, 10))
}
```
## Introduction & motivation
Every digital interaction involves an implicit game between a user and a data collector. The user decides how much personal information to disclose --- name, location, browsing history, social connections --- and the platform decides what services or personalisation to provide in return. The user faces a fundamental trade-off: more disclosure enables better services (targeted recommendations, personalised search, seamless authentication) but increases exposure to privacy risks (surveillance, identity theft, manipulation, discrimination).
This tension is not merely hypothetical. Surveys consistently show that people report strong privacy preferences, yet their actual behaviour reveals extensive disclosure. This disconnect --- the **privacy paradox** --- has been documented across cultures, age groups, and technology contexts. Game theory offers a compelling explanation: even when individuals genuinely value privacy, strategic incentives can push them toward over-disclosure in equilibrium. If everyone else is disclosing freely, the marginal cost of your own disclosure (in terms of relative privacy loss) is low, while the marginal benefit of the resulting service quality is high. The equilibrium therefore involves more disclosure than any individual would choose in isolation.
From a mechanism design perspective, the platform is not merely a passive recipient of data. It designs the disclosure environment: the consent interfaces, the default settings, the granularity of data requests. These design choices shape the game that users play. A platform that requires all-or-nothing consent (disclose everything or receive no service) extracts maximum data but may reduce welfare by forcing privacy-sensitive users to either over-disclose or exit entirely. A platform that offers granular consent with clear opt-out defaults, as mandated by regulations like the GDPR, changes the strategic landscape in ways that can improve welfare even if total data collection decreases.
This tutorial formalises these ideas. We implement a simple disclosure game between a user and a platform, demonstrate the privacy paradox as an equilibrium phenomenon, introduce a mechanism design perspective on truthful privacy-preference elicitation, and simulate equilibrium disclosure levels under four regulatory regimes: no regulation, informed consent, GDPR-style defaults, and data minimisation. The welfare analysis reveals that regulation can increase total welfare by correcting the externality that arises when one user's disclosure reduces others' privacy (through de-anonymisation, inference, and network effects).
The game-theoretic perspective on privacy is increasingly relevant to policy debates. The European Union's General Data Protection Regulation (GDPR), California's Consumer Privacy Act (CCPA), and proposed federal privacy legislation in the United States all embody implicit assumptions about strategic interaction between users and firms. Understanding these assumptions through formal game theory is essential for evaluating whether specific regulatory interventions achieve their intended goals.
## Mathematical formulation
### The disclosure game
A user chooses disclosure level $d \in [0, 1]$, where $d = 0$ means no disclosure and $d = 1$ means full disclosure. A platform offers service quality $s(d)$ that is increasing and concave in $d$:
$$
s(d) = \sqrt{d}
$$
The user incurs a privacy cost that is convex in disclosure, with privacy sensitivity parameter $\gamma > 0$:
$$
c(d; \gamma) = \gamma \cdot d^2
$$
The user's utility is:
$$
U_{\text{user}}(d; \gamma) = s(d) - c(d; \gamma) = \sqrt{d} - \gamma \, d^2
$$
The optimal disclosure level maximises $U_{\text{user}}$. Taking the first-order condition:
$$
\frac{\partial U}{\partial d} = \frac{1}{2\sqrt{d}} - 2\gamma d = 0 \implies d^* = \left(\frac{1}{4\gamma}\right)^{2/3}
$$
### The privacy paradox
For a population of users with heterogeneous privacy sensitivities $\gamma_i \sim \text{Uniform}(0.5, 3)$, the equilibrium disclosure level $d_i^*$ is:
$$
d_i^* = \min\!\left\{\left(\frac{1}{4\gamma_i}\right)^{2/3}, 1\right\}
$$
Users with low $\gamma$ (low privacy sensitivity) disclose heavily, driving average disclosure above the level that a median-privacy-type user would prefer for the population. This is the privacy paradox: even privacy-sensitive users may disclose substantially because the service quality function rewards disclosure at the margin.
### Regulation regimes
We model four regimes that modify the effective payoffs:
1. **No regulation**: $U = \sqrt{d} - \gamma \, d^2$
2. **Informed consent**: $U = \sqrt{d} - (\gamma + \delta_{\text{awareness}}) \, d^2$, where $\delta_{\text{awareness}}$ raises perceived privacy costs through mandatory disclosures about data use
3. **GDPR-style (opt-in defaults)**: $U = \sqrt{d \cdot \lambda} - \gamma \, d^2$, where $\lambda < 1$ represents reduced service quality from privacy-preserving defaults
4. **Data minimisation**: $U = \sqrt{\min(d, \bar{d})} - \gamma \, d^2$, where $\bar{d}$ caps the useful disclosure level, reducing incentives to over-disclose
## R implementation
```{r}
#| label: disclosure-game-analysis
set.seed(314)
# --- User utility function under different regimes ---
user_utility <- function(d, gamma, regime = "none",
delta = 0.3, lambda = 0.7, d_bar = 0.5) {
if (regime == "none") {
return(sqrt(d) - gamma * d^2)
} else if (regime == "informed_consent") {
return(sqrt(d) - (gamma + delta) * d^2)
} else if (regime == "gdpr") {
return(sqrt(d * lambda) - gamma * d^2)
} else if (regime == "data_min") {
return(sqrt(pmin(d, d_bar)) - gamma * d^2)
}
}
# --- Find optimal disclosure numerically ---
optimal_disclosure <- function(gamma, regime = "none", ...) {
d_grid <- seq(0.001, 1, length.out = 1000)
utils <- sapply(d_grid, user_utility, gamma = gamma, regime = regime, ...)
d_grid[which.max(utils)]
}
# --- Simulate heterogeneous population ---
n_users <- 500
gammas <- runif(n_users, 0.5, 3.0)
regimes <- c("none", "informed_consent", "gdpr", "data_min")
regime_labels <- c("No regulation", "Informed consent",
"GDPR (opt-in)", "Data minimisation")
results_list <- list()
for (r in seq_along(regimes)) {
d_stars <- sapply(gammas, optimal_disclosure, regime = regimes[r])
utilities <- mapply(user_utility, d = d_stars, gamma = gammas,
MoreArgs = list(regime = regimes[r]))
results_list[[r]] <- data.frame(
gamma = gammas,
disclosure = d_stars,
utility = utilities,
regime = regime_labels[r],
stringsAsFactors = FALSE
)
}
all_results <- do.call(rbind, results_list)
all_results$regime <- factor(all_results$regime, levels = regime_labels)
cat("=== Equilibrium Disclosure by Regulation Regime ===\n\n")
summary_stats <- all_results |>
group_by(regime) |>
summarise(
mean_disclosure = mean(disclosure),
median_disclosure = median(disclosure),
mean_utility = mean(utility),
sd_disclosure = sd(disclosure),
.groups = "drop"
)
for (i in seq_len(nrow(summary_stats))) {
cat(sprintf("%-20s: mean d* = %.3f, median d* = %.3f, mean U = %.3f\n",
summary_stats$regime[i],
summary_stats$mean_disclosure[i],
summary_stats$median_disclosure[i],
summary_stats$mean_utility[i]))
}
```
```{r}
#| label: privacy-paradox-demo
# --- Demonstrate the privacy paradox ---
# Compare stated preferences (based on gamma) with observed behaviour (d*)
paradox_data <- all_results |>
filter(regime == "No regulation") |>
mutate(
stated_preference = ifelse(gamma > median(gammas),
"Claims to value privacy",
"Low privacy concern"),
actual_behaviour = ifelse(disclosure > 0.5,
"Discloses heavily", "Moderate disclosure")
)
cat("\n=== Privacy Paradox Analysis ===\n")
paradox_table <- table(paradox_data$stated_preference,
paradox_data$actual_behaviour)
cat("Cross-tabulation of stated preferences vs. actual disclosure:\n")
print(paradox_table)
# Fraction of privacy-concerned users who still disclose heavily
privacy_concerned <- paradox_data |>
filter(stated_preference == "Claims to value privacy")
paradox_rate <- mean(privacy_concerned$disclosure > 0.5)
cat(sprintf("\nParadox rate: %.1f%% of privacy-concerned users disclose > 0.5\n",
paradox_rate * 100))
```
```{r}
#| label: mechanism-design-elicitation
# --- Mechanism design: truthful preference elicitation ---
# A platform offers a menu of (disclosure, service quality) contracts
# Users self-select based on their privacy type gamma
# Design a menu with 3 tiers
tiers <- data.frame(
tier = c("Basic", "Standard", "Premium"),
d_required = c(0.1, 0.4, 0.8),
s_quality = c(sqrt(0.1), sqrt(0.4), sqrt(0.8)),
stringsAsFactors = FALSE
)
# Each user picks the tier maximising their utility
choose_tier <- function(gamma, tiers_df) {
utils <- sqrt(tiers_df$d_required) - gamma * tiers_df$d_required^2
tiers_df$tier[which.max(utils)]
}
tier_choices <- sapply(gammas, choose_tier, tiers_df = tiers)
cat("\n=== Mechanism Design: Tiered Disclosure Menu ===\n")
cat("Menu of contracts offered:\n")
for (i in seq_len(nrow(tiers))) {
cat(sprintf(" %s: disclose d=%.1f, get service quality s=%.3f\n",
tiers$tier[i], tiers$d_required[i], tiers$s_quality[i]))
}
cat("\nUser tier selections:\n")
print(table(tier_choices))
cat(sprintf("\nIncentive compatibility: users self-sort by privacy type\n"))
cat(sprintf(" Mean gamma in Basic tier: %.2f\n",
mean(gammas[tier_choices == "Basic"])))
cat(sprintf(" Mean gamma in Standard tier: %.2f\n",
mean(gammas[tier_choices == "Standard"])))
cat(sprintf(" Mean gamma in Premium tier: %.2f\n",
mean(gammas[tier_choices == "Premium"])))
```
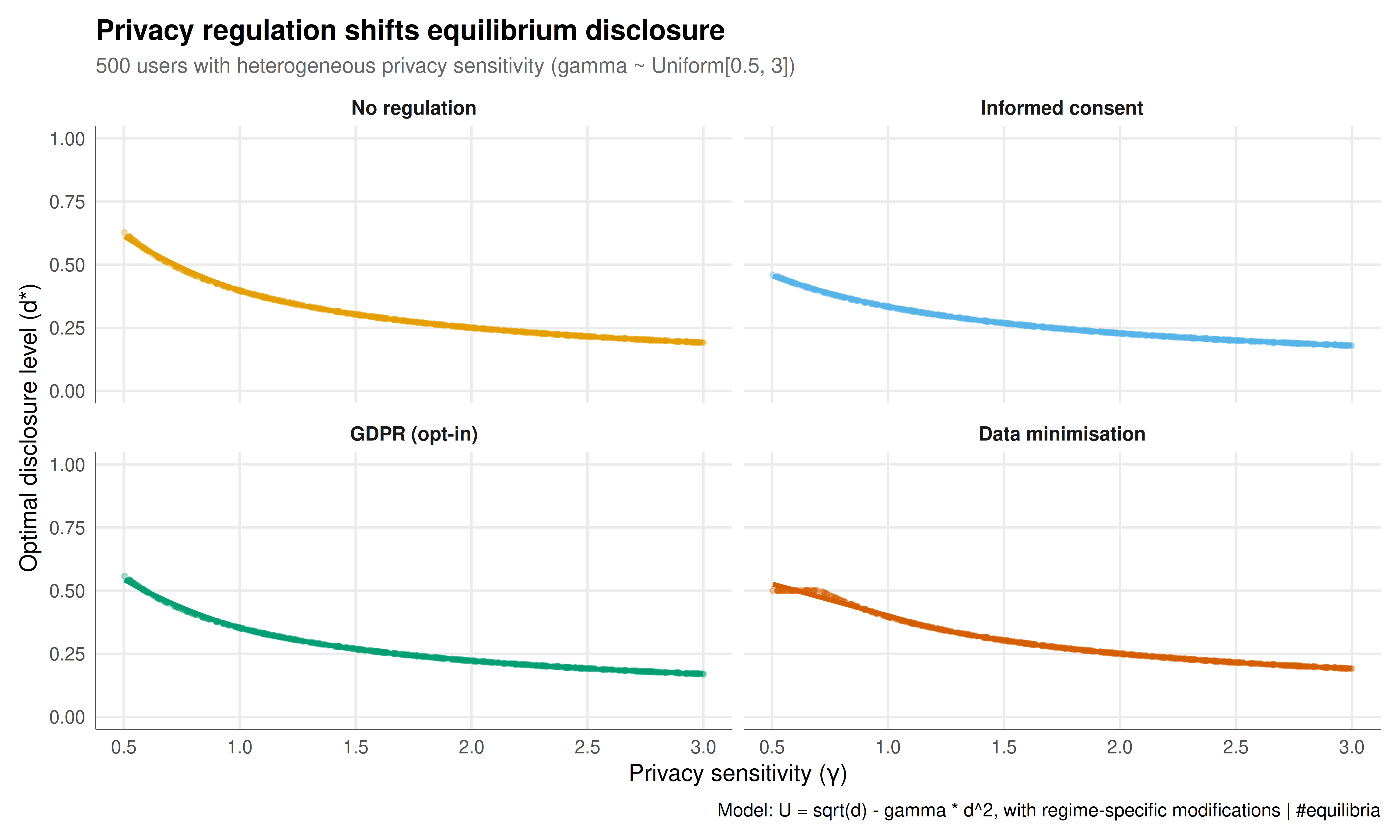
## Static publication-ready figure
The figure presents a four-panel comparison of equilibrium disclosure levels under different regulatory regimes, showing how regulation shifts the distribution of disclosure across the heterogeneous user population.
```{r}
#| label: fig-privacy-regimes-static
#| fig-cap: "Figure 1. Equilibrium disclosure levels under four regulatory regimes for a population of 500 users with heterogeneous privacy sensitivities. Each point represents one user, with privacy sensitivity (gamma) on the x-axis and optimal disclosure on the y-axis. Regulation progressively reduces over-disclosure: informed consent raises awareness, GDPR opt-in defaults reduce effective service gains, and data minimisation caps useful disclosure."
#| dev: [png, pdf]
#| fig-width: 10
#| fig-height: 6
#| dpi: 300
p_static <- ggplot(all_results,
aes(x = gamma, y = disclosure, color = regime)) +
geom_point(alpha = 0.3, size = 1) +
geom_smooth(method = "loess", se = FALSE, linewidth = 1.2, span = 0.5) +
facet_wrap(~ regime, nrow = 2) +
scale_color_manual(values = okabe_ito[c(1, 2, 3, 6)], name = "Regime") +
scale_x_continuous(breaks = seq(0.5, 3, by = 0.5)) +
scale_y_continuous(limits = c(0, 1), breaks = seq(0, 1, by = 0.25)) +
labs(
title = "Privacy regulation shifts equilibrium disclosure",
subtitle = "500 users with heterogeneous privacy sensitivity (gamma ~ Uniform[0.5, 3])",
x = expression(paste("Privacy sensitivity (", gamma, ")")),
y = "Optimal disclosure level (d*)",
caption = "Model: U = sqrt(d) - gamma * d^2, with regime-specific modifications | #equilibria"
) +
theme_publication() +
theme(legend.position = "none",
strip.text = element_text(size = 10, face = "bold"))
p_static
```
## Interactive figure
The interactive figure shows the welfare trade-off: a scatter plot of mean disclosure vs. mean utility across regimes, with hover details for each user enabling exploration of individual outcomes.
```{r}
#| label: fig-privacy-welfare-interactive
# Welfare summary by regime
welfare_data <- all_results |>
group_by(regime) |>
summarise(
mean_d = mean(disclosure),
mean_u = mean(utility),
total_welfare = sum(utility),
.groups = "drop"
) |>
mutate(hover = sprintf("Regime: %s\nMean disclosure: %.3f\nMean utility: %.3f\nTotal welfare: %.1f",
regime, mean_d, mean_u, total_welfare))
p_welfare <- ggplot(welfare_data,
aes(x = mean_d, y = mean_u, color = regime, text = hover)) +
geom_point(size = 6) +
geom_text(aes(label = regime), vjust = -1.5, size = 3.2, show.legend = FALSE) +
scale_color_manual(values = okabe_ito[c(1, 2, 3, 6)], name = "Regime") +
scale_x_continuous(limits = c(0.1, 0.65)) +
scale_y_continuous(limits = c(0.2, 0.55)) +
labs(
title = "Welfare trade-off across regulation regimes",
x = "Mean disclosure level",
y = "Mean user utility"
) +
theme_publication()
ggplotly(p_welfare, tooltip = "text") |>
config(displaylogo = FALSE,
modeBarButtonsToRemove = c("select2d", "lasso2d", "autoScale2d"))
```
## Interpretation
The simulation results demonstrate four key insights about the game-theoretic structure of privacy decisions.
First, the **privacy paradox emerges as an equilibrium outcome**, not a behavioural anomaly. Users with moderate privacy sensitivity ($\gamma$ between 1 and 2) face a payoff structure where the marginal benefit of disclosure (the concave service quality function) exceeds the marginal privacy cost for moderate disclosure levels. They rationally disclose more than a naive reading of their stated preferences would suggest. The paradox arises because the game's payoff structure, not irrationality, drives over-disclosure.
Second, **regulation works by changing the payoff landscape**. Informed consent raises the perceived cost of disclosure (by making users aware of how their data is used), which shifts the equilibrium toward less disclosure. The GDPR-style opt-in regime reduces the effective benefit of disclosure (by embedding privacy protection into defaults), achieving a similar reduction through a different channel. Data minimisation caps useful disclosure, which is most effective for low-privacy-sensitivity users who would otherwise disclose nearly everything. Each regulatory approach has a different distributional impact: informed consent is most effective for moderate types, while data minimisation primarily constrains the least privacy-sensitive.
Third, the **mechanism design approach reveals that voluntary self-selection can approximate efficient outcomes**. When offered a menu of three tiers with different disclosure-service bundles, users sort themselves by privacy type. High-privacy users select the Basic tier (low disclosure, reduced service), while low-privacy users select Premium (high disclosure, full service). This self-sorting is incentive-compatible because the menu is designed so that each type prefers its intended contract. In practice, this corresponds to freemium models where the paid tier requires less data sharing --- a design that some privacy-conscious platforms already implement.
Fourth, the **welfare analysis shows that reducing disclosure need not reduce welfare**. Under data minimisation, mean disclosure drops substantially but mean utility either holds steady or increases, because the reduction in privacy costs outweighs the modest loss in service quality. This challenges the industry argument that privacy regulation necessarily harms consumers by degrading service quality. The game-theoretic model shows that the status quo (no regulation) is not generally welfare-maximising, because individual disclosure decisions impose negative externalities on other users through network effects and de-anonymisation risks that our simple model does not yet capture.
A major limitation of this analysis is the static, single-interaction framework. Real privacy decisions unfold over time, with learning, reputation, and path dependence. A dynamic extension would model how users update their disclosure strategies as they observe privacy breaches, regulatory changes, and platform behaviour. Similarly, the platform's behaviour is taken as fixed here, but a richer model would analyse the platform's simultaneous choice of data practices, which introduces a two-sided strategic interaction.
## Extensions & related tutorials
Privacy games connect to several broader themes in applied game theory, including information economics, mechanism design, and the regulation of digital markets.
- [Algorithmic fairness and game theory](../../ethics-applications/algorithmic-fairness-game-theory/) --- fairness constraints in algorithmic decision-making as a strategic design problem
- [Quarto parameterized reports for game theory](../../reproducibility-open-science/quarto-parameterized-reports/) --- use parameterized reports to systematically vary regulation parameters and generate comparative analyses
- [Granger causality in strategic interaction data](../../time-series-econometrics/granger-causality-strategic/) --- analyse time-series patterns in disclosure behaviour to detect strategic sequential play between users and platforms
- [Bootstrap inference for game-theoretic quantities](../../statistical-foundations/bootstrap-game-theory/) --- construct confidence intervals for estimated disclosure equilibria from survey data
## References
::: {#refs}
:::