13 Author-Level Analysis and Disambiguation
13.4 Worked example
13.4.4 Publication timeline
annual <- works_slim |>
group_by(year) |>
summarise(n_pubs = n(), cites = sum(cited_by_count), .groups = "drop") |>
mutate(cum_cites = cumsum(cites))
ggplot(annual, aes(x = year)) +
geom_col(aes(y = n_pubs), fill = palette_sci(1), width = 0.7) +
geom_line(aes(y = cum_cites / max(cum_cites) * max(n_pubs)),
colour = palette_sci(2)[2], linewidth = 1) +
scale_y_continuous(
name = "Publications per year",
sec.axis = sec_axis(~ . / max(annual$n_pubs) * max(annual$cum_cites),
name = "Cumulative citations")
) +
labs(x = "Year") +
theme_sci()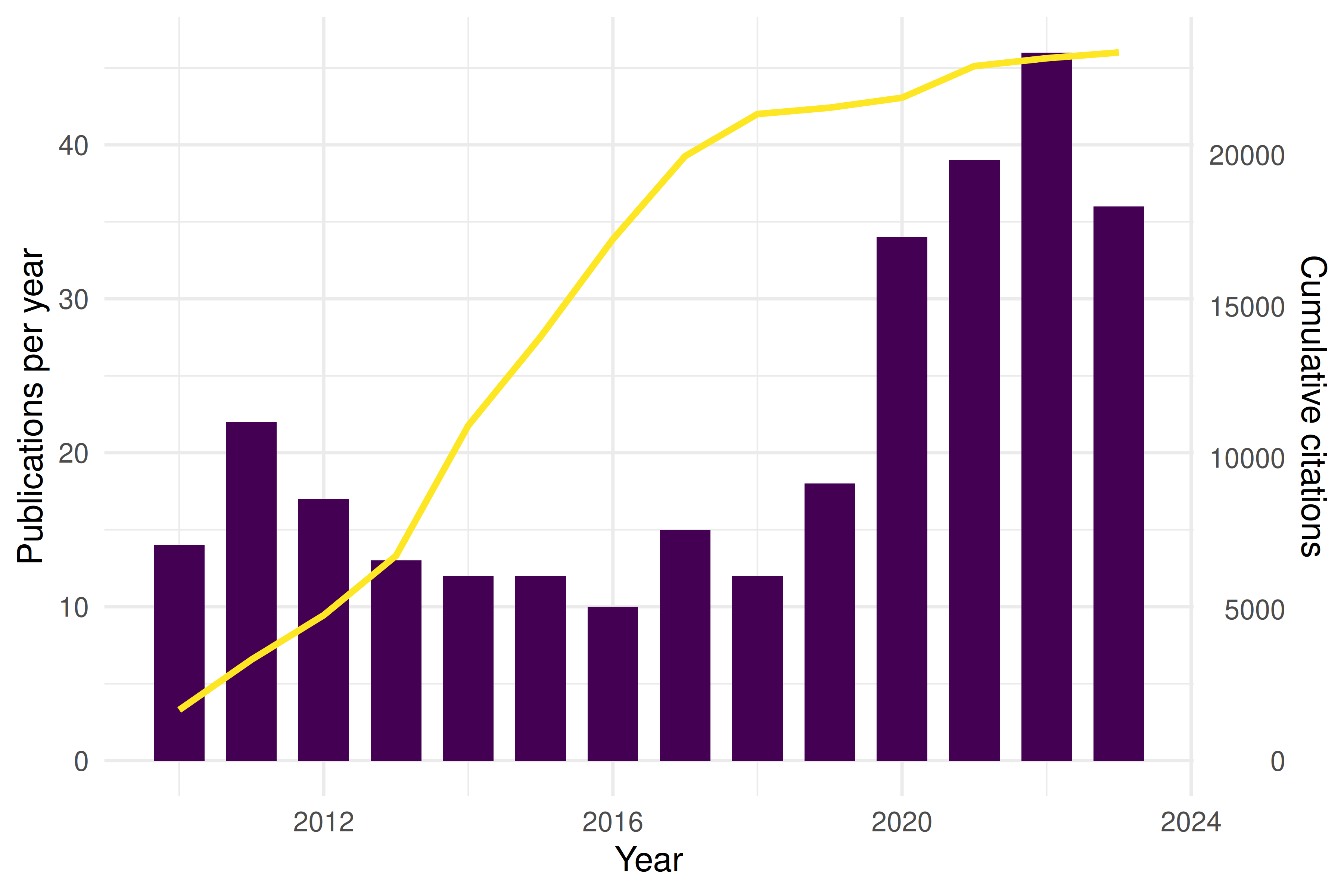
Figure 13.1: Annual publication output and cumulative citation count.
13.4.5 Top venues
venue_counts <- works_slim |>
filter(!is.na(source_display_name)) |>
count(source_display_name, sort = TRUE) |>
head(10)
ggplot(venue_counts, aes(x = n, y = reorder(source_display_name, n))) +
geom_col(fill = palette_sci(1)) +
labs(x = "Number of articles", y = NULL) +
theme_sci()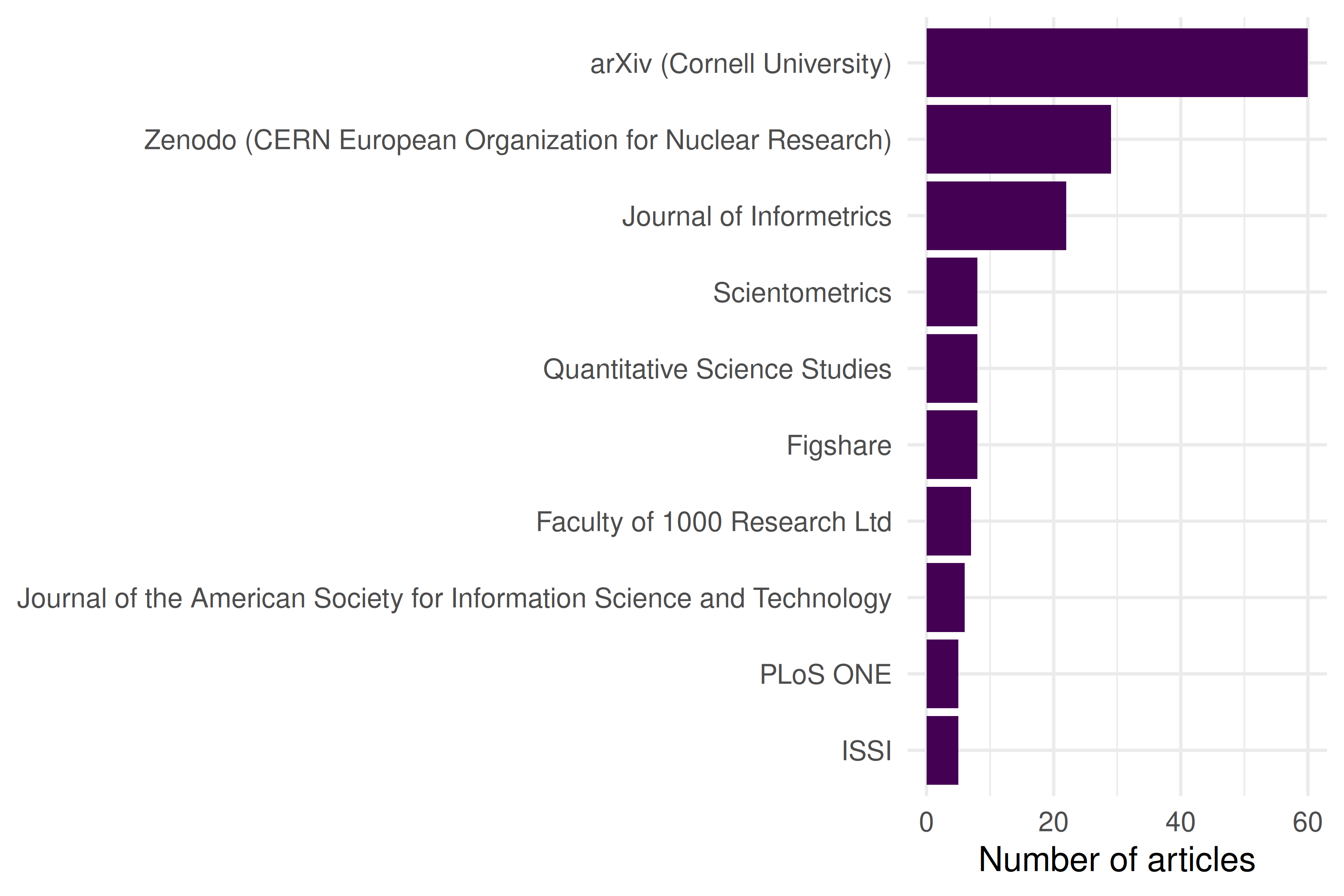
Figure 13.2: Top 10 venues by number of publications for this author.
13.4.6 Checking for name variants
if ("display_name_alternatives" %in% names(author_info)) {
cat("Known name variants:\n")
print(author_info$display_name_alternatives)
} else {
cat("No alternative display names recorded in this entity.\n")
}#> Known name variants:
#> [[1]]
#> [1] "L Waltman" "L. Waltman" "LUDO WALTMAN"
#> [4] "Ludo Waltman" "Waltman, L." "Waltman, L. (Ludo)"
#> [7] "Waltman, L.R." "Waltman, LR (Ludo)" "Waltman, Ludo"13.7 Limitations and responsible use
- Disambiguation is imperfect. OpenAlex’s algorithm will sometimes split one person into multiple entities or merge distinct individuals. Always validate profiles manually for high-stakes analyses.
- ORCID coverage is uneven. Researchers in the Global South, early-career scholars, and those in humanities adopt ORCID at lower rates. Filtering to ORCID-linked authors introduces bias.
- The Matthew effect. Established researchers accumulate citations disproportionately (Merton 1968). Author-level metrics favour seniority and visibility, not necessarily quality or originality.
- Career breaks and part-time research. Indicators like the h-index penalise researchers who take parental leave, work part-time, or switch careers. The m-quotient is only a rough correction (Hirsch 2005).
- Never evaluate individuals by numbers alone (Hicks et al. 2015; American Society for Cell Biology 2012). Author profiles should supplement, not replace, reading the actual work.
13.9 Common pitfalls
- Trusting a single database. OpenAlex may lack works indexed only in domain-specific databases (e.g., SSRN, arXiv preprints not yet linked). Cross-check with ORCID profiles.
- Ignoring co-author contributions. Raw publication counts treat single-author and 50-author papers equally. Consider fractional counting for productivity analysis.
- Comparing across career stages. An early-career researcher with h = 8 after 5 years may be more productive than a senior researcher with h = 25 after 30 years. Use the m-quotient or age-normalised indicators.
- Conflating author-level and paper-level metrics. An author’s h-index says nothing about which of their papers are excellent and which are not.
13.11 Solutions
Solutions are provided in 2.11.
This book was built by the bookdown R package.