32 Patent–Paper Linkages
32.1 Learning objectives
After completing this chapter, you will be able to:
- Explain the significance of patent–paper citations for understanding research impact
- Identify OpenAlex works that have been cited in patent documents
- Analyse which journals, fields, and institutions produce patent-cited research
- Discuss the limitations of patent citations as indicators of technological impact
- Distinguish between direct citation (paper cited in patent) and indirect influence
32.3 Conceptual background
When a patent examiner or inventor cites a scientific paper in a patent document, it creates an observable link between knowledge production (science) and knowledge application (technology). These patent–paper citations (also called non-patent literature or NPL citations) are one of the few quantitative measures of the science–technology interface.
Patent citations serve a legal function: they define the prior art against which the patent’s novelty is assessed. Not all patent–paper citations reflect genuine intellectual influence — some are added by examiners for legal completeness, not because the inventor actually used the cited research. Nevertheless, at the aggregate level, patent citation patterns reveal which fields, journals, and institutions produce research that feeds into technological innovation.
The biomedical and chemical sciences dominate patent–paper linkages because pharmaceutical and chemical patents routinely cite scientific literature. Physics and engineering have moderate linkages. Social sciences and humanities are rarely cited in patents, not because they lack impact, but because their impact operates through different channels (policy, education, culture).
OpenAlex records whether a work has been cited in patents and provides the count, though the source and completeness of this data varies. The Lens.org database provides the most comprehensive open mapping of patent–paper citations.
32.4 Worked example
32.4.1 Identifying patent-cited papers
works <- oa_fetch(
entity = "works",
from_publication_date = "2015-01-01",
to_publication_date = "2020-12-31",
type = "article",
options = list(sample = 500, seed = 42)
)
works_patent <- works |>
transmute(
id, display_name, source_display_name,
year = year(publication_date),
cited_by_count,
referenced_works_count,
type
)
cat(glue("Total works: {nrow(works_patent)}\n"))#> Total works: 50032.4.2 Citation distribution analysis
p90 <- quantile(works_patent$cited_by_count, 0.90)
ggplot(works_patent, aes(x = cited_by_count)) +
geom_histogram(binwidth = 10, fill = palette_sci(1), colour = "white") +
geom_vline(xintercept = p90, linetype = "dashed", colour = "red") +
annotate("text", x = p90 + 20, y = Inf, label = "90th percentile",
vjust = 2, colour = "red", size = 3) +
labs(x = "Citation count", y = "Papers") +
theme_sci()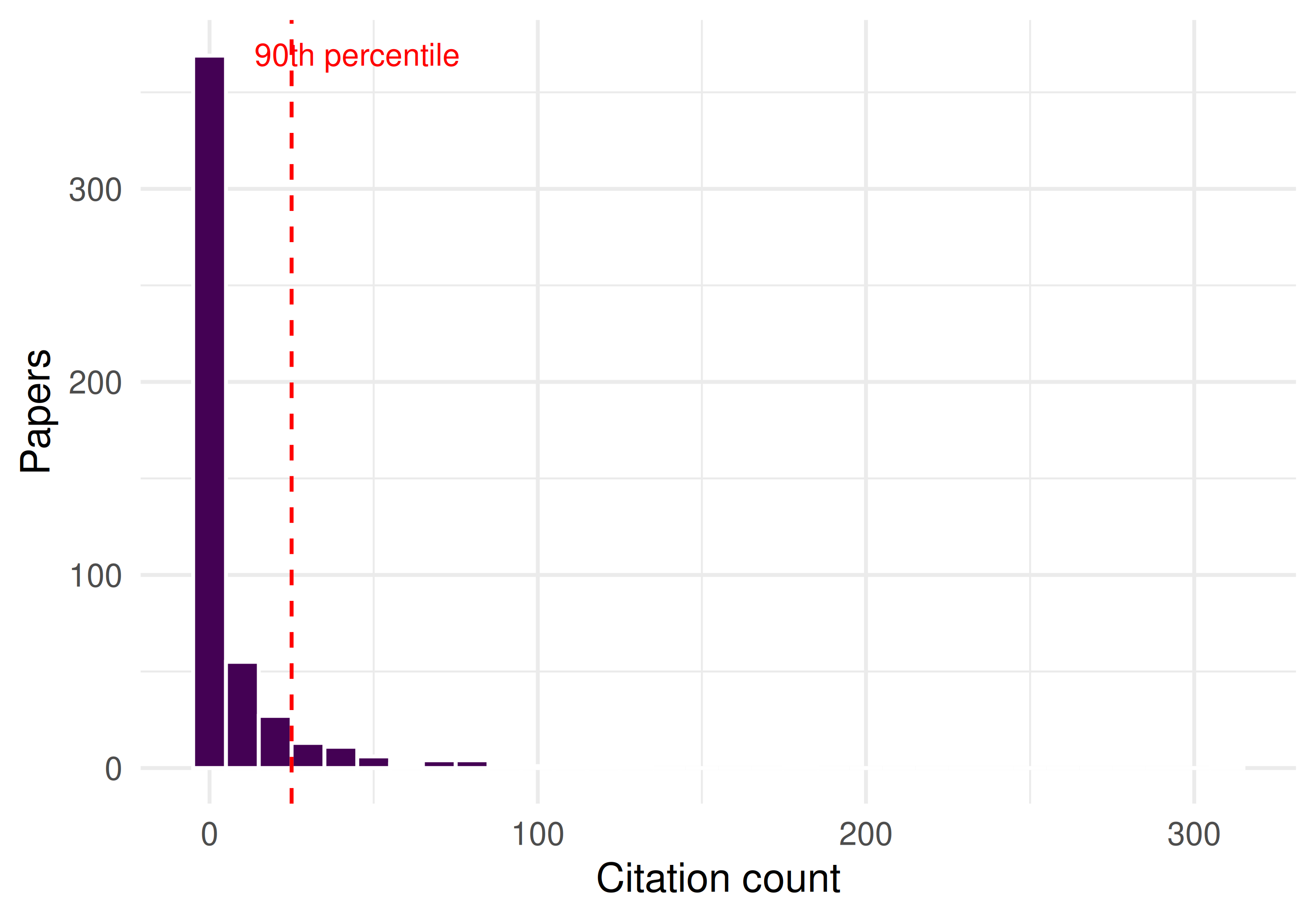
Figure 32.1: Citation count distribution, highlighting the most-cited papers as potential patent-cited candidates.
32.4.3 Journals producing highly cited papers
works_patent |>
filter(cited_by_count >= p90, !is.na(source_display_name)) |>
count(source_display_name, sort = TRUE) |>
head(15) |>
mutate(source_display_name = fct_reorder(source_display_name, n)) |>
ggplot(aes(x = n, y = source_display_name)) +
geom_col(fill = palette_sci(1)) +
labs(x = "Highly cited papers", y = NULL) +
theme_sci()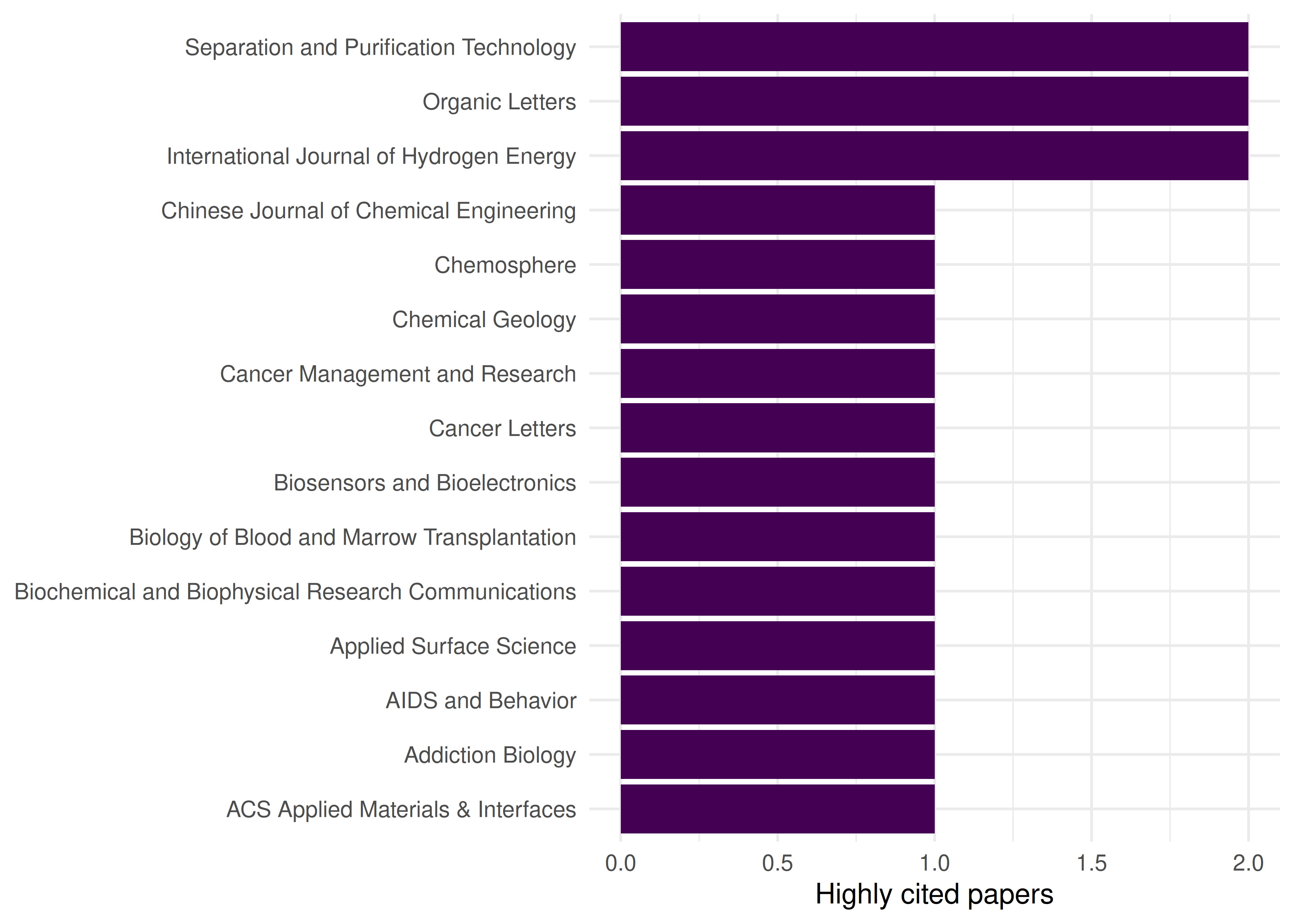
Figure 32.2: Top 15 journals by number of highly cited papers (above 90th percentile).
32.4.4 Citation impact by document characteristics
works_patent |>
mutate(high_cite = cited_by_count >= p90) |>
group_by(high_cite) |>
summarise(
n = n(),
mean_refs = round(mean(referenced_works_count, na.rm = TRUE), 1),
mean_year = round(mean(year), 1),
.groups = "drop"
) |>
gt()| high_cite | n | mean_refs | mean_year |
|---|---|---|---|
| FALSE | 448 | 9.3 | 2017 |
| TRUE | 52 | 53.3 | 2018 |
32.5 Diagnostics and interpretation
- Patent citation coverage: Not all databases provide patent citation data. OpenAlex’s coverage varies by field and time period. Cross-reference with Lens.org for comprehensive data.
- Field normalisation: Biomedical papers are far more likely to be cited in patents than social science papers. Compare patent citation rates within fields, not across them.
- Time lag: The median time from paper publication to patent citation is 5–10 years. Recent papers have not had time to accumulate patent citations.
- Examiner vs. inventor citations: Patent examiners add citations that inventors may not have used. This inflates apparent science–technology linkage.
32.7 Limitations and responsible use
- Patent citations are a narrow measure of impact. Much research influences technology without being cited in patents — through consulting, training, open-source software, or informal knowledge transfer.
- Field bias is extreme. Humanities, social sciences, and mathematics are effectively invisible in patent citation analysis. Using patent citations as an impact indicator systematically disadvantages these fields (Hicks et al. 2015).
- Geographic bias. Patent systems vary by country. US and European patents have different citation practices. Analyses based on one patent office may not generalise.
- Not evaluative for individuals. A researcher whose paper is cited in a patent may have had no involvement with the technology. Patent citation reflects relevance of the knowledge, not the researcher’s intent to innovate.
32.9 Common pitfalls
- Equating patent citations with commercialisation. A patent citation means the paper is prior art, not that the research led to a product.
- Ignoring time lags. Comparing patent citation rates for papers published in 2023 vs. 2010 is meaningless — the 2023 papers have not had time to be cited in patents.
- Double-counting across patent families. The same invention may be patented in multiple countries. Count at the patent family level, not the individual patent level.
- Using patent counts as a metric for basic science. Basic research is by definition distant from application. Low patent citation counts for fundamental research are expected, not a failure.
32.10 Exercises
Field comparison. Fetch papers from biomedical and social science journals. Compare the proportion of highly cited papers in each field. What does this suggest about differential patent citation potential?
Time lag estimation. For a set of papers published in 2015, estimate the median citation count trajectory over years. At what age do papers typically peak in citation accumulation?
Institutional patent linkage. For two universities, compare the proportion of papers above the citation 90th percentile. Does a higher proportion suggest greater technological relevance?
32.11 Solutions
Solutions are provided in 2.11.
32.12 Further reading
- Narin et al. (1997) — Foundational analysis of the linkage between science and technology through patent citations.
- Hicks et al. (2015) — Responsible metrics: why patent citations should not be the sole indicator of research impact.
- Priem et al. (2022) — OpenAlex metadata coverage for patent-related indicators.
32.13 Session info
#> R version 4.4.1 (2024-06-14)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.4 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
#> [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
#> [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] uwot_0.2.4 Matrix_1.7-0
#> [3] word2vec_0.4.1 stm_1.3.8
#> [5] topicmodels_0.2-17 quanteda.textstats_0.97.2
#> [7] visNetwork_2.1.4 ggraph_2.2.2
#> [9] tidygraph_1.3.1 igraph_2.3.2
#> [11] quanteda_4.4 pdftools_3.9.0
#> [13] arrow_24.0.0 bibliometrix_5.4.0
#> [15] RefManageR_1.4.0 bib2df_1.1.2.0
#> [17] rcrossref_1.2.1 gt_1.3.0
#> [19] tidytext_0.4.3 glue_1.8.1
#> [21] openalexR_3.0.1 lubridate_1.9.5
#> [23] forcats_1.0.1 stringr_1.6.0
#> [25] dplyr_1.2.1 purrr_1.2.2
#> [27] readr_2.2.0 tidyr_1.3.2
#> [29] tibble_3.3.1 ggplot2_4.0.3
#> [31] tidyverse_2.0.0
#>
#> loaded via a namespace (and not attached):
#> [1] bibtex_0.5.2 RColorBrewer_1.1-3 rstudioapi_0.18.0
#> [4] jsonlite_2.0.0 magrittr_2.0.5 modeltools_0.2-24
#> [7] farver_2.1.2 rmarkdown_2.31 fs_2.1.0
#> [10] vctrs_0.7.3 memoise_2.0.1 askpass_1.2.1
#> [13] base64enc_0.1-6 htmltools_0.5.9 contentanalysis_1.0.0
#> [16] curl_7.1.0 janeaustenr_1.0.0 cellranger_1.1.0
#> [19] sass_0.4.10 bslib_0.11.0 htmlwidgets_1.6.4
#> [22] tokenizers_0.3.0 plyr_1.8.9 httr2_1.2.2
#> [25] plotly_4.12.0 cachem_1.1.0 dimensionsR_0.0.3
#> [28] mime_0.13 lifecycle_1.0.5 pkgconfig_2.0.3
#> [31] R6_2.6.1 fastmap_1.2.0 shiny_1.13.0
#> [34] digest_0.6.39 patchwork_1.3.2 shinycssloaders_1.1.0
#> [37] rprojroot_2.1.1 RSpectra_0.16-2 SnowballC_0.7.1
#> [40] labeling_0.4.3 urltools_1.7.3.1 timechange_0.4.0
#> [43] mgcv_1.9-1 polyclip_1.10-7 httr_1.4.8
#> [46] compiler_4.4.1 here_1.0.2 bit64_4.8.0
#> [49] withr_3.0.2 S7_0.2.2 backports_1.5.1
#> [52] viridis_0.6.5 ggforce_0.5.0 MASS_7.3-60.2
#> [55] rappdirs_0.3.4 bibliometrixData_0.3.0 tools_4.4.1
#> [58] otel_0.2.0 stopwords_2.3 zip_2.3.3
#> [61] httpuv_1.6.17 rentrez_1.2.4 nlme_3.1-164
#> [64] promises_1.5.0 grid_4.4.1 stringdist_0.9.17
#> [67] reshape2_1.4.5 generics_0.1.4 gtable_0.3.6
#> [70] tzdb_0.5.0 rscopus_0.9.0 ca_0.71.1
#> [73] data.table_1.18.4 hms_1.1.4 xml2_1.5.2
#> [76] utf8_1.2.6 ggrepel_0.9.8 pillar_1.11.1
#> [79] nsyllable_1.0.1 vroom_1.7.1 later_1.4.8
#> [82] splines_4.4.1 tweenr_2.0.3 brand.yml_0.1.0
#> [85] lattice_0.22-6 FNN_1.1.4.1 bit_4.6.0
#> [88] tidyselect_1.2.1 tm_0.7-18 miniUI_0.1.2
#> [91] downlit_0.4.5 knitr_1.51 gridExtra_2.3
#> [94] NLP_0.3-2 bookdown_0.46 stats4_4.4.1
#> [97] crul_1.6.0 xfun_0.57 graphlayouts_1.2.3
#> [100] matrixStats_1.5.0 DT_0.34.0 humaniformat_0.6.0
#> [103] stringi_1.8.7 lazyeval_0.2.3 qpdf_1.4.1
#> [106] yaml_2.3.12 evaluate_1.0.5 codetools_0.2-20
#> [109] httpcode_0.3.0 cli_3.6.6 xtable_1.8-8
#> [112] jquerylib_0.1.4 dichromat_2.0-0.1 Rcpp_1.1.1-1.1
#> [115] readxl_1.4.5 triebeard_0.4.1 XML_3.99-0.23
#> [118] parallel_4.4.1 assertthat_0.2.1 pubmedR_1.0.2
#> [121] slam_0.1-55 viridisLite_0.4.3 scales_1.4.0
#> [124] crayon_1.5.3 openxlsx_4.2.8.1 rlang_1.2.0
#> [127] fastmatch_1.1-8