8 Building Reproducible Corpora
8.1 Learning objectives
After completing this chapter, you will be able to:
- Deduplicate bibliographic records by DOI and by approximate title matching
- Resolve identifiers across databases (OpenAlex ID, DOI, PMID)
- Recognize author name disambiguation challenges and apply basic heuristics
- Standardize institutional affiliations using ROR identifiers
- Save a clean corpus in an efficient format (Parquet) for downstream analysis
8.3 Conceptual background
Raw bibliographic data is messy. Records from different sources may describe the same paper with different metadata, the same author under different name variants, and the same institution under dozens of spelling variations. Building a clean, reproducible corpus requires systematic attention to three problems:
Deduplication. When merging data from multiple sources, the same publication may appear multiple times. DOI-based deduplication is the gold standard, but not all records have DOIs. Fuzzy title matching provides a fallback but is error-prone for short or generic titles.
Author disambiguation. “J. Smith” could be dozens of different people. OpenAlex uses machine-learning-based author clustering to assign persistent author IDs, but errors persist — especially for common names and authors who change institutions (Priem et al. 2022).
Affiliation standardization. Institutional names appear in countless variants (“MIT”, “Massachusetts Institute of Technology”, “Mass. Inst. Tech.”). The Research Organization Registry (ROR) provides a curated set of persistent identifiers for research organizations. OpenAlex maps many affiliations to ROR IDs, but coverage is incomplete.
8.4 Worked example
8.4.1 Fetching raw data
works <- oa_fetch(
entity = "works",
search = "bibliometrics",
from_publication_date = "2021-01-01",
to_publication_date = "2023-12-31",
options = list(sample = 300, seed = 42)
)
cat(glue("Raw records: {nrow(works)}\n"))#> Raw records: 3008.4.3 Fuzzy title deduplication
For records without DOIs, we use approximate string matching.
no_doi <- works_deduped |> filter(is.na(doi))
if (nrow(no_doi) > 1) {
title_lower <- tolower(no_doi$display_name)
dist_matrix <- stringdist::stringdistmatrix(title_lower, method = "jw")
potential_dupes <- which(as.matrix(dist_matrix) < 0.1 &
as.matrix(dist_matrix) > 0, arr.ind = TRUE)
potential_dupes <- potential_dupes[potential_dupes[, 1] < potential_dupes[, 2], , drop = FALSE]
cat(glue("Potential fuzzy duplicates (no DOI): {nrow(potential_dupes)} pairs\n"))
} else {
cat("No records without DOI to fuzzy-match.\n")
}#> Potential fuzzy duplicates (no DOI): 0 pairs8.4.4 Affiliation extraction and ROR mapping
affiliations <- works_deduped |>
select(id, authorships) |>
unnest(authorships, names_sep = "_") |>
unnest(authorships_affiliations, names_sep = "_") |>
select(work_id = id,
author_name = authorships_display_name,
institution = authorships_affiliations_display_name) |>
filter(!is.na(institution))
top_institutions <- affiliations |>
count(institution, sort = TRUE) |>
head(15)
top_institutions#> # A tibble: 15 × 2
#> institution n
#> <chr> <int>
#> 1 Capital Medical University 18
#> 2 Beijing Friendship Hospital 16
#> 3 National Taiwan University of Science and Technology 12
#> 4 University of Bari Aldo Moro 11
#> 5 Chinese Academy of Medical Sciences & Peking Union Medical College 10
#> 6 Indonesia University of Education 10
#> 7 McMaster University 10
#> 8 National University of Malaysia 10
#> 9 Universiti Teknologi MARA 10
#> 10 Dongguan People’s Hospital 9
#> 11 Guangdong Medical College 9
#> 12 North American Vascular Biology Organization 9
#> 13 Universitas Jember 9
#> 14 University of Ilorin 9
#> 15 Diponegoro University 88.4.5 Saving as Parquet
corpus_clean <- works_deduped |>
select(id, display_name, publication_date, cited_by_count, doi, source_display_name, abstract)
out_path <- here::here("data", "corpus_sample.parquet")
write_parquet(corpus_clean, out_path)
cat(glue("Saved {nrow(corpus_clean)} records to {out_path}\n"))#> Saved 300 records to /home/runner/work/scientometrics-in-r/scientometrics-in-r/data/corpus_sample.parquet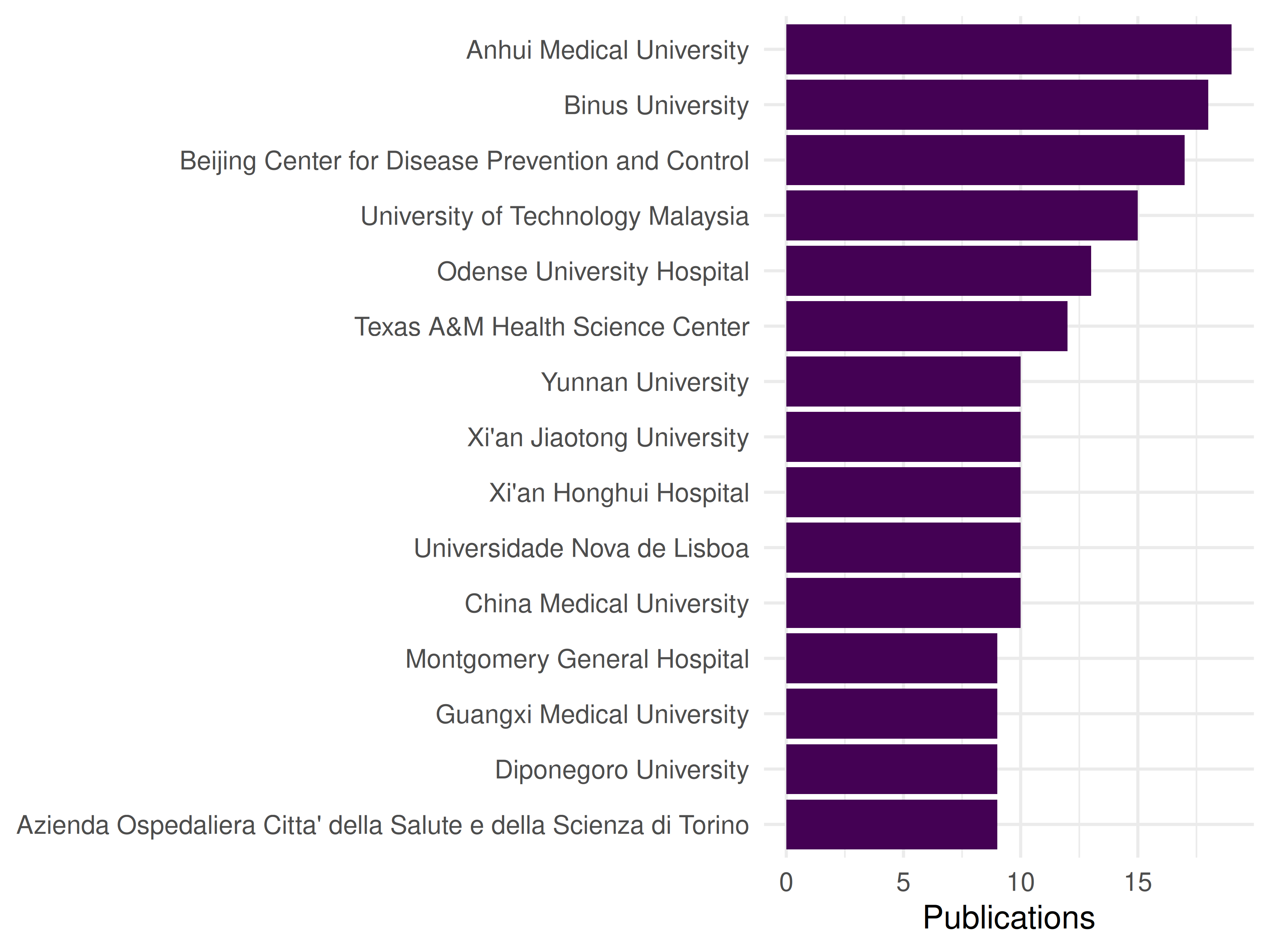
8.5 Diagnostics and interpretation
After cleaning:
- Deduplication rate: A rate above 5% suggests either a multi-source merge or a query that returns overlapping result pages.
- DOI coverage: The proportion of records with DOIs determines how effective DOI-based deduplication can be.
- Affiliation coverage: Check what fraction of author records have institutional affiliations. Low coverage limits institutional analysis.
- Parquet file size: Parquet is columnar and compressed. A 10,000-record corpus typically compresses to under 1 MB.
8.7 Limitations and responsible use
- Fuzzy matching is imperfect. Jaro-Winkler similarity can produce both false positives (different papers with similar titles) and false negatives (same paper with different title versions). Always spot-check.
- Author disambiguation remains unsolved. No automated method achieves perfect accuracy. Report the disambiguation method used and its known error rate.
- Affiliation data is noisy. Even with ROR mapping, temporary affiliations, joint appointments, and name changes create ambiguity. Never use affiliation data as ground truth without validation (Hicks et al. 2015).
8.9 Common pitfalls
- Deduplicating before merging. Always merge first, then deduplicate. Deduplicating each source independently misses cross-source duplicates.
- Trusting DOIs blindly. Some records have incorrect DOIs (typos, test DOIs, placeholder values). Validate a sample.
- Ignoring records without DOIs. Discarding them biases the corpus toward recent, well-indexed publications.
- Not documenting cleaning steps. Every deduplication or name-standardization step should be logged for reproducibility.
8.10 Exercises
DOI coverage by year. Compute the DOI coverage rate by publication year in the sample. Is there a trend?
Name variants. Find authors in the sample who appear under multiple name spellings. What heuristics could you use to merge them?
ROR lookup. Use the ROR API to resolve the top 5 institutions in your corpus to their official ROR identifiers.
8.11 Solutions
Solutions are provided in 2.11.
8.13 Session info
#> R version 4.4.1 (2024-06-14)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.4 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
#> [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
#> [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] arrow_24.0.0 bibliometrix_5.4.0 RefManageR_1.4.0 bib2df_1.1.2.0
#> [5] rcrossref_1.2.1 gt_1.3.0 tidytext_0.4.3 glue_1.8.1
#> [9] openalexR_3.0.1 lubridate_1.9.5 forcats_1.0.1 stringr_1.6.0
#> [13] dplyr_1.2.1 purrr_1.2.2 readr_2.2.0 tidyr_1.3.2
#> [17] tibble_3.3.1 ggplot2_4.0.3 tidyverse_2.0.0
#>
#> loaded via a namespace (and not attached):
#> [1] bibtex_0.5.2 RColorBrewer_1.1-3 rstudioapi_0.18.0
#> [4] jsonlite_2.0.0 magrittr_2.0.5 farver_2.1.2
#> [7] rmarkdown_2.31 fs_2.1.0 vctrs_0.7.3
#> [10] memoise_2.0.1 askpass_1.2.1 base64enc_0.1-6
#> [13] htmltools_0.5.9 contentanalysis_1.0.0 curl_7.1.0
#> [16] janeaustenr_1.0.0 cellranger_1.1.0 sass_0.4.10
#> [19] bslib_0.11.0 htmlwidgets_1.6.4 pdftools_3.9.0
#> [22] tokenizers_0.3.0 plyr_1.8.9 httr2_1.2.2
#> [25] plotly_4.12.0 cachem_1.1.0 dimensionsR_0.0.3
#> [28] igraph_2.3.2 mime_0.13 lifecycle_1.0.5
#> [31] pkgconfig_2.0.3 Matrix_1.7-0 R6_2.6.1
#> [34] fastmap_1.2.0 shiny_1.13.0 digest_0.6.39
#> [37] shinycssloaders_1.1.0 rprojroot_2.1.1 SnowballC_0.7.1
#> [40] labeling_0.4.3 urltools_1.7.3.1 timechange_0.4.0
#> [43] httr_1.4.8 compiler_4.4.1 here_1.0.2
#> [46] bit64_4.8.0 withr_3.0.2 S7_0.2.2
#> [49] backports_1.5.1 viridis_0.6.5 rappdirs_0.3.4
#> [52] bibliometrixData_0.3.0 tools_4.4.1 otel_0.2.0
#> [55] stopwords_2.3 zip_2.3.3 httpuv_1.6.17
#> [58] rentrez_1.2.4 promises_1.5.0 grid_4.4.1
#> [61] stringdist_0.9.17 generics_0.1.4 gtable_0.3.6
#> [64] tzdb_0.5.0 rscopus_0.9.0 ca_0.71.1
#> [67] data.table_1.18.4 hms_1.1.4 xml2_1.5.2
#> [70] utf8_1.2.6 ggrepel_0.9.8 pillar_1.11.1
#> [73] later_1.4.8 brand.yml_0.1.0 lattice_0.22-6
#> [76] bit_4.6.0 tidyselect_1.2.1 miniUI_0.1.2
#> [79] downlit_0.4.5 knitr_1.51 gridExtra_2.3
#> [82] bookdown_0.46 crul_1.6.0 xfun_0.57
#> [85] DT_0.34.0 humaniformat_0.6.0 visNetwork_2.1.4
#> [88] stringi_1.8.7 lazyeval_0.2.3 qpdf_1.4.1
#> [91] yaml_2.3.12 evaluate_1.0.5 codetools_0.2-20
#> [94] httpcode_0.3.0 cli_3.6.6 xtable_1.8-8
#> [97] jquerylib_0.1.4 dichromat_2.0-0.1 Rcpp_1.1.1-1.1
#> [100] readxl_1.4.5 triebeard_0.4.1 XML_3.99-0.23
#> [103] parallel_4.4.1 assertthat_0.2.1 pubmedR_1.0.2
#> [106] viridisLite_0.4.3 scales_1.4.0 openxlsx_4.2.8.1
#> [109] rlang_1.2.0