29 Gender and Equity Analysis
29.1 Learning objectives
After completing this chapter, you will be able to:
- Explain the challenges of gender inference from author names
- Apply name-based gender classification and assess its limitations
- Analyse gender representation in authorship positions (first, last, corresponding)
- Compute gender-disaggregated citation and productivity statistics
- Articulate why gender is not binary and why name-based inference introduces systematic bias
29.3 Conceptual background
Research on gender disparities in science has documented persistent gaps in publication rates, citation counts, funding success, and career progression. Bibliometric analysis can quantify these gaps at scale, but the methods used raise serious ethical and technical concerns.
Gender inference from names is the most common approach. Services like genderize.io, Gender API, and the R package gender assign a probabilistic gender (typically male/female) based on first names and country of origin. This approach has fundamental limitations: it enforces a binary classification, it fails for names common across genders, it has low accuracy for non-Western names, and it misclassifies non-binary and transgender researchers. Despite these limitations, name-based inference remains widely used because self-reported gender data is rarely available in bibliometric databases.
Authorship position carries different significance across disciplines. In biomedical sciences, the last author is typically the senior researcher and the first author the primary contributor. In other fields, authorship is alphabetical. Gender analysis of authorship positions must account for these disciplinary conventions.
Documented gender disparities include: women are underrepresented as first and last authors in most fields (Larivière et al. 2013); women’s papers receive fewer citations on average, even after controlling for field and year; and women are less likely to be invited as reviewers or editors. These patterns reflect systemic inequities, not differences in research quality.
Hicks et al. (2015) and American Society for Cell Biology (2012) both emphasise that metrics should not be used in ways that perpetuate existing biases. Gender analysis in bibliometrics should aim to reveal disparities for policy intervention, not to evaluate individual researchers.
29.4 Worked example
29.4.2 Simple name-based gender proxy
We use a minimal heuristic for demonstration. In production work, use a validated gender-inference service with probabilistic output and country context.
common_female <- c("maria", "anna", "li", "sarah", "jennifer", "jessica",
"elena", "nina", "laura", "julia", "diana", "sandra")
common_male <- c("john", "david", "michael", "james", "robert", "peter",
"mark", "thomas", "paul", "daniel", "andreas", "martin")
authors <- authors |>
mutate(
gender_proxy = case_when(
first_name %in% common_female ~ "female",
first_name %in% common_male ~ "male",
TRUE ~ NA_character_
)
)
classified <- authors |> filter(!is.na(gender_proxy))
cat(glue("Classified: {nrow(classified)} / {nrow(authors)} ({scales::percent(nrow(classified)/nrow(authors))})\n"))#> Classified: 47 / 914 (5%)29.4.3 Gender representation
classified |>
count(gender_proxy) |>
mutate(pct = n / sum(n)) |>
ggplot(aes(x = gender_proxy, y = pct, fill = gender_proxy)) +
geom_col(show.legend = FALSE) +
scale_y_continuous(labels = scales::percent) +
scale_fill_manual(values = palette_sci(2)) +
labs(x = "Inferred gender", y = "Proportion") +
theme_sci()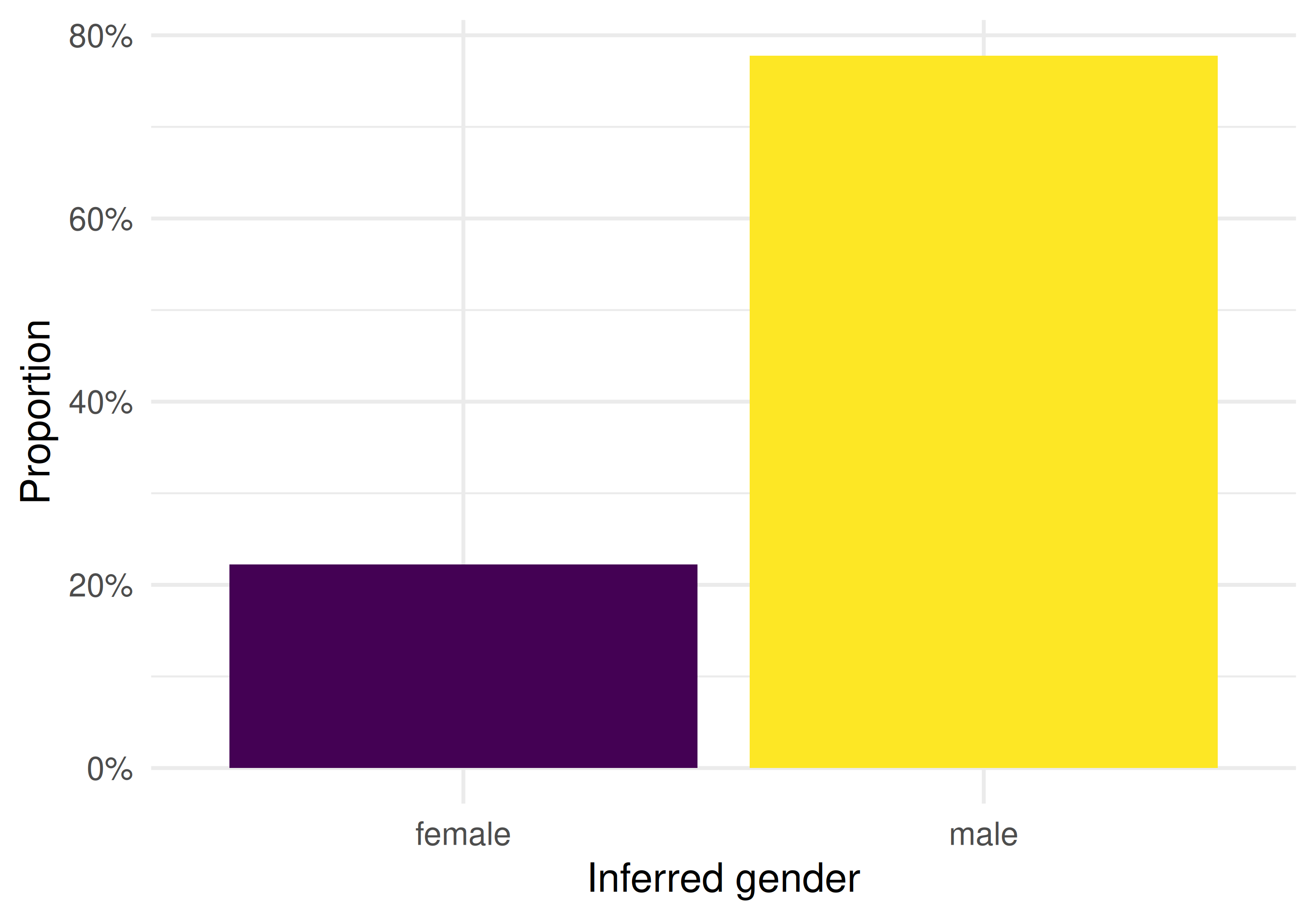
Figure 29.1: Gender representation among classifiable author names.
29.4.4 Authorship position analysis
position_data <- works |>
select(work_id = id, authorships) |>
unnest(authorships, names_sep = "_") |>
group_by(work_id) |>
mutate(
n_authors = n(),
author_position = case_when(
row_number() == 1 ~ "first",
row_number() == n() & n() > 1 ~ "last",
TRUE ~ "middle"
)
) |>
ungroup() |>
mutate(first_name = str_to_lower(str_extract(authorships_display_name, "^\\S+"))) |>
mutate(
gender_proxy = case_when(
first_name %in% common_female ~ "female",
first_name %in% common_male ~ "male",
TRUE ~ NA_character_
)
) |>
filter(!is.na(gender_proxy))
position_summary <- position_data |>
count(author_position, gender_proxy) |>
group_by(author_position) |>
mutate(pct = n / sum(n)) |>
ungroup()
position_summary |> gt()| author_position | gender_proxy | n | pct |
|---|---|---|---|
| first | female | 3 | 0.188 |
| first | male | 13 | 0.812 |
| last | female | 6 | 0.375 |
| last | male | 10 | 0.625 |
| middle | female | 7 | 0.467 |
| middle | male | 8 | 0.533 |
ggplot(position_summary, aes(x = author_position, y = pct, fill = gender_proxy)) +
geom_col(position = "dodge") +
scale_y_continuous(labels = scales::percent) +
scale_fill_manual(values = palette_sci(2)) +
labs(x = "Author position", y = "Proportion", fill = "Inferred gender") +
theme_sci()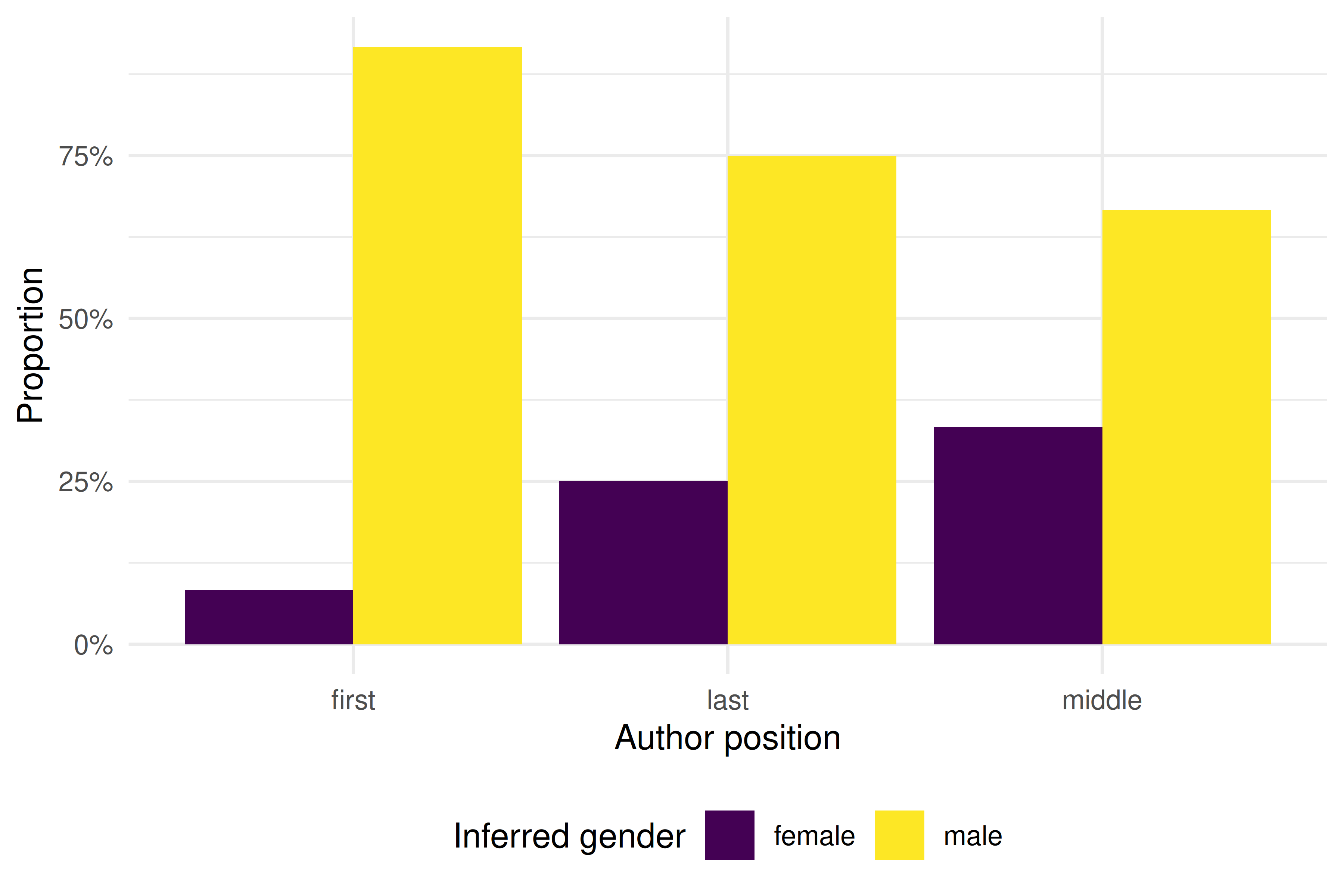
Figure 29.2: Gender representation by authorship position.
29.5 Diagnostics and interpretation
- Classification rate: A low classification rate (< 40%) means results may not be representative. Names from East Asia, South Asia, and Africa are particularly poorly served by English-trained gender classifiers.
- Confidence thresholds: Use probabilistic classifiers with confidence thresholds (e.g., only classify names with > 90% probability). Report the threshold and the proportion of unclassified names.
- Disciplinary norms: Authorship order conventions vary. In fields with alphabetical ordering, “first author” has no special significance.
- Sample size: Gender disparities may be small. Ensure sample sizes are sufficient for meaningful comparisons.
29.7 Limitations and responsible use
- Gender is not binary. Name-based inference forces a male/female classification that excludes non-binary, genderqueer, and gender-non-conforming researchers. This is a fundamental limitation, not merely a technical one.
- Name-based inference is systematically biased. Accuracy is lower for non-Western names, transliterated names, and unisex names. Results should always report classification accuracy and unclassified rates by name origin.
- Correlation is not causation. If women receive fewer citations, this may reflect systemic bias in citing behaviour, differences in subfield distribution, career interruptions, or other structural factors — not differences in research quality.
- Privacy and consent. Inferring gender from names without consent raises ethical concerns. Report aggregate statistics, never individual-level gender assignments.
- Use for equity, not evaluation. Gender analysis should identify systemic disparities for policy intervention, never evaluate individual researchers (Hicks et al. 2015; American Society for Cell Biology 2012).
29.9 Common pitfalls
- Reporting gender ratios without uncertainty. Name-based inference is probabilistic. Report confidence intervals or sensitivity analyses.
- Ignoring unclassified names. Dropping unclassified names biases the sample toward Western, easily classified names.
- Assuming authorship order is universal. Alphabetical ordering in mathematics and economics means authorship position analysis is meaningless.
- Conflating gender with sex. Bibliometric gender analysis infers social gender from names, not biological sex. The two are distinct concepts.
29.10 Exercises
Cross-journal comparison. Compare gender representation across three journals in different fields. Are there differences in the proportion of female first authors?
Temporal trends. Track the proportion of female first authors by year. Is there evidence of increasing representation over time?
Citation gap. Compare mean citations for papers with female vs. male first authors, controlling for publication year. What does the gap look like?
29.11 Solutions
Solutions are provided in 2.11.
29.12 Further reading
- Larivière et al. (2013) — Large-scale analysis of gender disparities in scientific authorship.
- Hicks et al. (2015) — The Leiden Manifesto: responsible metrics that do not perpetuate bias.
- American Society for Cell Biology (2012) — DORA: recommendations against metrics-based evaluation that disadvantages underrepresented groups.
29.13 Session info
#> R version 4.4.1 (2024-06-14)
#> Platform: x86_64-pc-linux-gnu
#> Running under: Ubuntu 24.04.4 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
#>
#> locale:
#> [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
#> [4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
#> [7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
#> [10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] uwot_0.2.4 Matrix_1.7-0
#> [3] word2vec_0.4.1 stm_1.3.8
#> [5] topicmodels_0.2-17 quanteda.textstats_0.97.2
#> [7] visNetwork_2.1.4 ggraph_2.2.2
#> [9] tidygraph_1.3.1 igraph_2.3.2
#> [11] quanteda_4.4 pdftools_3.9.0
#> [13] arrow_24.0.0 bibliometrix_5.4.0
#> [15] RefManageR_1.4.0 bib2df_1.1.2.0
#> [17] rcrossref_1.2.1 gt_1.3.0
#> [19] tidytext_0.4.3 glue_1.8.1
#> [21] openalexR_3.0.1 lubridate_1.9.5
#> [23] forcats_1.0.1 stringr_1.6.0
#> [25] dplyr_1.2.1 purrr_1.2.2
#> [27] readr_2.2.0 tidyr_1.3.2
#> [29] tibble_3.3.1 ggplot2_4.0.3
#> [31] tidyverse_2.0.0
#>
#> loaded via a namespace (and not attached):
#> [1] bibtex_0.5.2 RColorBrewer_1.1-3 rstudioapi_0.18.0
#> [4] jsonlite_2.0.0 magrittr_2.0.5 modeltools_0.2-24
#> [7] farver_2.1.2 rmarkdown_2.31 fs_2.1.0
#> [10] vctrs_0.7.3 memoise_2.0.1 askpass_1.2.1
#> [13] base64enc_0.1-6 htmltools_0.5.9 contentanalysis_1.0.0
#> [16] curl_7.1.0 janeaustenr_1.0.0 cellranger_1.1.0
#> [19] sass_0.4.10 bslib_0.11.0 htmlwidgets_1.6.4
#> [22] tokenizers_0.3.0 plyr_1.8.9 httr2_1.2.2
#> [25] plotly_4.12.0 cachem_1.1.0 dimensionsR_0.0.3
#> [28] mime_0.13 lifecycle_1.0.5 pkgconfig_2.0.3
#> [31] R6_2.6.1 fastmap_1.2.0 shiny_1.13.0
#> [34] digest_0.6.39 patchwork_1.3.2 shinycssloaders_1.1.0
#> [37] rprojroot_2.1.1 RSpectra_0.16-2 SnowballC_0.7.1
#> [40] labeling_0.4.3 urltools_1.7.3.1 timechange_0.4.0
#> [43] mgcv_1.9-1 polyclip_1.10-7 httr_1.4.8
#> [46] compiler_4.4.1 here_1.0.2 bit64_4.8.0
#> [49] withr_3.0.2 S7_0.2.2 backports_1.5.1
#> [52] viridis_0.6.5 ggforce_0.5.0 MASS_7.3-60.2
#> [55] rappdirs_0.3.4 bibliometrixData_0.3.0 tools_4.4.1
#> [58] otel_0.2.0 stopwords_2.3 zip_2.3.3
#> [61] httpuv_1.6.17 rentrez_1.2.4 nlme_3.1-164
#> [64] promises_1.5.0 grid_4.4.1 stringdist_0.9.17
#> [67] reshape2_1.4.5 generics_0.1.4 gtable_0.3.6
#> [70] tzdb_0.5.0 rscopus_0.9.0 ca_0.71.1
#> [73] data.table_1.18.4 hms_1.1.4 xml2_1.5.2
#> [76] utf8_1.2.6 ggrepel_0.9.8 pillar_1.11.1
#> [79] nsyllable_1.0.1 vroom_1.7.1 later_1.4.8
#> [82] splines_4.4.1 tweenr_2.0.3 brand.yml_0.1.0
#> [85] lattice_0.22-6 FNN_1.1.4.1 bit_4.6.0
#> [88] tidyselect_1.2.1 tm_0.7-18 miniUI_0.1.2
#> [91] downlit_0.4.5 knitr_1.51 gridExtra_2.3
#> [94] NLP_0.3-2 bookdown_0.46 stats4_4.4.1
#> [97] crul_1.6.0 xfun_0.57 graphlayouts_1.2.3
#> [100] matrixStats_1.5.0 DT_0.34.0 humaniformat_0.6.0
#> [103] stringi_1.8.7 lazyeval_0.2.3 qpdf_1.4.1
#> [106] yaml_2.3.12 evaluate_1.0.5 codetools_0.2-20
#> [109] httpcode_0.3.0 cli_3.6.6 xtable_1.8-8
#> [112] jquerylib_0.1.4 dichromat_2.0-0.1 Rcpp_1.1.1-1.1
#> [115] readxl_1.4.5 triebeard_0.4.1 XML_3.99-0.23
#> [118] parallel_4.4.1 assertthat_0.2.1 pubmedR_1.0.2
#> [121] slam_0.1-55 viridisLite_0.4.3 scales_1.4.0
#> [124] crayon_1.5.3 openxlsx_4.2.8.1 rlang_1.2.0
#> [127] fastmatch_1.1-8